顔認識技術を利用したアプリケーションは身近なところにあります。たとえば、カメラで映した顔に猫耳やリボンなどのスタンプを自由に追加できる加工アプリ「SNOW」や、ビデオ会議ツール「Zoom」、「Microsoft Teams」で使用できるフィルター機能などがあります。これらの機能は、フェイストラッキング技術を利用しています。
この技術はアプリだけでなく、ウェブブラウザ上でも実現できます。今回は、Googleが開発した機械学習用JavaScriptライブラリ「TensorFlow.js」を使って、ウェブカメラでリアルタイムに顔が認識されるデモを作成してみました。
TensorFlow.jsとは
TensorFlow.jsは、Pythonで広く利用されている機械学習ライブラリ「TensorFlow」をJavaScript用にラップしたもので、ブラウザ上で機械学習モデルを手軽に利用できるようにするものです。たとえば、以下のようなモデルが提供されています。
- 顔認識モデル:顔の検出と特徴点の抽出が可能
- 手のポーズ認識モデル:手の形状や動きをリアルタイムで検出できる
- 画像分類モデル:画像を特定のカテゴリに分類する
- テキスト有害度検出モデル:テキストの内容が有害かどうかを判定する
ほかにも、さまざまな用途に合ったモデルが提供されています。
今回は、顔認識モデル「face-detection」と「face-landmarks-detection」を紹介します。
▲ face-detectionを利用したオリジナルのデモ。詳細は後述します。
face-detection
face-detectionモデルは、画像や動画から顔を検出するためのモデルです。公式のデモページをご覧ください。
コードを少し見てみましょう。まず初めに、顔の検出器を作成します。
const model = faceDetection.SupportedModels.MediaPipeFaceDetector;
const detectorConfig = {
runtime: 'mediapipe', // or 'tfjs'
}
const detector = await faceDetection.createDetector(model, detectorConfig);
次に、作成した顔の検出器を使用して顔を検出します。
const faces = await detector.estimateFaces(camera.video, {flipHorizontal: false});
estimateFaces関数は、第一引数に「顔を検出したい画像 or 動画」を指定し、第二引数に「オプションの設定」を指定します。flipHorizontalは、水平方向の反転を制御するための設定です。
flipHorizontal: false:入力ビデオがそのままの向きで処理されます。通常のカメラ映像では、左右反転は行われません。flipHorizontal: true:入力ビデオが左右反転されて処理されます。自撮りカメラやウェブカメラを使用している場合に、鏡のように見えるようにするために設定します。
facesには、検出された顔が配列として格納されます。検出された顔のリストには、それぞれ「境界ボックス」と「キーポイント」の配列が含まれます。キーポイントには、x座標とy座標に加えて、位置を特定するための名前(右目、左目、鼻、口、右耳、左耳)が存在します。
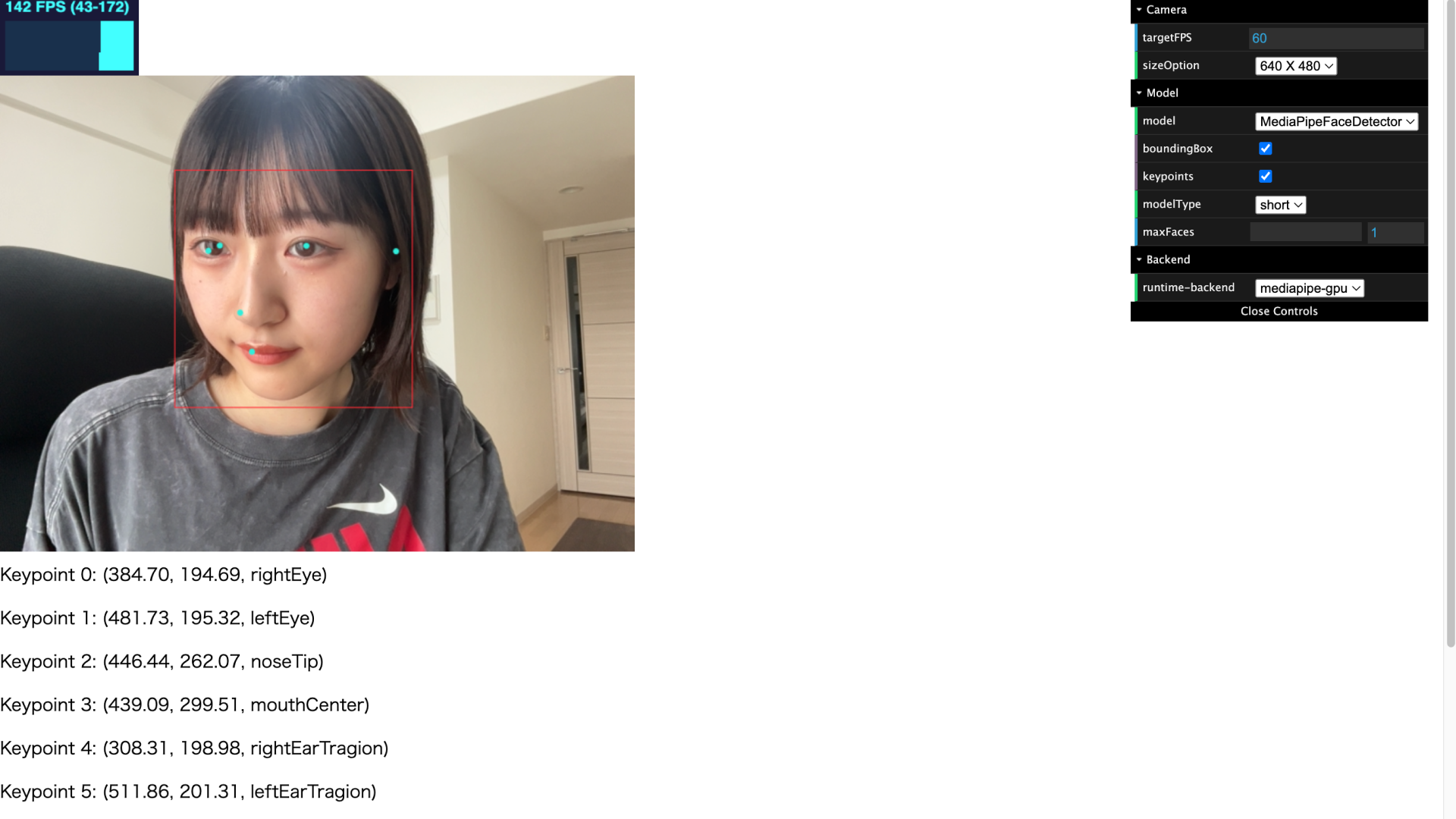
検出されたキーポイントの座標と名前を画面に表示してみました。それぞれのポイントは、名前を用いて指定できます。
デモ - face-detection(2D)
face-detectionモデルを使用してデモを作成してみました。ウェブカメラを使用してリアルタイムで顔認識を行い、好きなスタンプ画像を選んで顔に貼り付けられます。スタンプは顔の動きに合わせて配置されます。
以下の流れで処理を行っています。
- ウェブカメラの映像を取得し、
<canvas>へ描画する - TensorFlow.jsの
MediaPipe Face Detectionを使用して、ウェブカメラの映像中の顔をリアルタイムで検知 - 検知された座標に基づいて、
<canvas>にスタンプ画像を配置する
ウェブカメラの映像取得
まず、ウェブカメラの映像を取得し、その映像を<canvas>に描画するための準備をします。
async function enableCam() {
const constraints = {
audio: false,
video: true,
width: 640,
height: 480,
};
try {
const stream = await navigator.mediaDevices.getUserMedia(constraints);
webcamElement.srcObject = stream;
return new Promise((resolve) => {
webcamElement.onloadedmetadata = () => {
webcamElement.play();
resolve();
};
});
} catch (error) {
console.error('Error accessing webcam: ', error);
alert('カメラのアクセスに失敗しました。カメラのアクセス権限を確認してください。');
}
}
ウェブカメラの映像を取得し、その映像を<video>に設定します。具体的には、ウェブカメラの映像ストリームを取得し、それをwebcamElementという<video>のsrcObjectプロパティに設定します。
この<video>はTensorFlow.jsで顔認識を行うために使用されます。実際に画面上に表示されているウェブカメラ映像は、<canvas>に描画されています。
TensorFlow.jsへデータを渡す
取得したウェブカメラの映像をTensorFlow.jsに渡して顔を検出します。
async function estimateFaces() {
const estimationConfig = { flipHorizontal: false };
results = await detector.estimateFaces(webcamElement, estimationConfig);
}
estimateFaces関数は、<video>の映像データをTensorFlow.jsの顔検出モデルに渡し、顔の位置を検出します。
スタンプ画像を描画する
検出された顔の位置に基づいて、<canvas>にスタンプ画像を描画します。ひとつの<canvas>上に、ウェブカメラの映像とスタンプ画像を重ねて配置しているメージです。
画像をそのまま配置しただけでは、顔を傾けたときに座標がズレてしまったり、顔を遠ざけたときにスタンプ画像のサイズが変わらなかったりという問題があります。この問題を解決するために、以下の計算を行います。
たとえば顔の傾きは、右目と左目の位置関係から取得しています。
// 顔の傾きを計算する
const dx = rightEye.x - leftEye.x;
const dy = rightEye.y - leftEye.y;
const angle = Math.atan2(dy, dx);
顔の幅は、左右の耳の距離から取得しています。
// 顔の幅を計算する(左右の耳の距離)
const faceWidth = Math.hypot((rightEarTragion.x - leftEarTragion.x), (rightEarTragion.y - leftEarTragion.y));
const baseFaceWidth = 200; // 基準となる顔の幅
// スケールを計算する
const scale = baseFaceWidth / faceWidth;
リアルタイムで検出した顔のパーツにスタンプ画像を配置するための一連の手順を説明しました。これにより、顔を傾けたりカメラから遠ざかったりしても、スタンプ画像が顔に追従するようになります。詳しいソースコードは、GitHubリポジトリを参照してください。
しかし、たとえば真横を向いたとき(顔をY軸まわりに回転させたとき)に少し違和感があるかと思います。スタンプ画像だけが、正面を向いたままになっているのです。
次にご紹介するface-landmarks-detectionで、この問題を解決してみたいと思います。
face-landmarks-detection
face-landmarks-detectionモデルでは、顔の詳細な特徴点をリアルタイムで取得できます。こちらも、公式のデモページをご覧ください。
コードを確認してみましょう。先ほどのface-detectionと同様に、顔の検出器を作成しています。顔のランドマーク検出モデルにはMediaPipeFaceMeshを指定しています。MediaPipeFaceMeshモデルは、顔の詳細なランドマーク(点)を検出できます。
const model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
const detectorConfig = {
runtime: 'mediapipe', // or 'tfjs'
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh',
}
const detector = await faceLandmarksDetection.createDetector(model, detectorConfig);
次に、検出器を使用して顔を検出します。
const faces = await detector.estimateFaces(camera.video, {flipHorizontal: false});
検出された顔のリストには、face-detectionと同様に、それぞれ「境界ボックス」と「キーポイント」の配列が含まれています。異なるのは、MediaPipeFaceMeshが468個のキーポイントを返すという点です。
各キーポイントにも違いがあります。face-landmarks-detectionでは、x座標とy座標に加えて、z座標が取得できます。zは頭の中心を原点とする深さを表し、値が小さいほどキーポイントがカメラに近くなります。取得できるキーポイントは、公式のページをご確認ください。
名前は、「lips」や「leftEye」など、一部のキーポイントには存在しますが、すべてのキーポイントにラベルが付いているわけではありません。


face-detectionの例と同様に、キーポイントの座標と名前を表示してみました。名前の含まれているキーポイントと、含まれていないキーポイントが存在することがわかりますね。
デモ - face-landmarks-detection(3D)
face-landmarks-detectionモデルを用いて、先ほどのface-detectionのデモを応用させてみました。
以下の流れで処理を行っています。
- ウェブカメラの映像を取得し、
<video>に描画する - TensorFlow.jsの
MediaPipe Face Landmarks Detectionを使用して、ウェブカメラの映像中の顔をリアルタイムで検知 - 検出された座標に基づいて、オリジナルのスタンプ画像を
<canvas>の3D空間上に配置する
face-landmarks-detectionのデモは2Dではなく3Dのため、3D描画ライブラリとして「Three.js」を使用します。本デモのThree.jsのバージョンは0.165.0です。
使用するスタンプ画像は、PlaneGeometryで定義した平面(プレーン)に貼り付けて描画することにします。face-detectionのデモと異なり、「<video>をcanvas空間上ではなくHTMLタグとして配置している」点に注意してください。理由は後述します。
2点、ポイントがあります。「検出器から取得できるz座標の扱い」と「顔の傾きをどう取得するか」についてです。
ポイント1:z座標の扱い
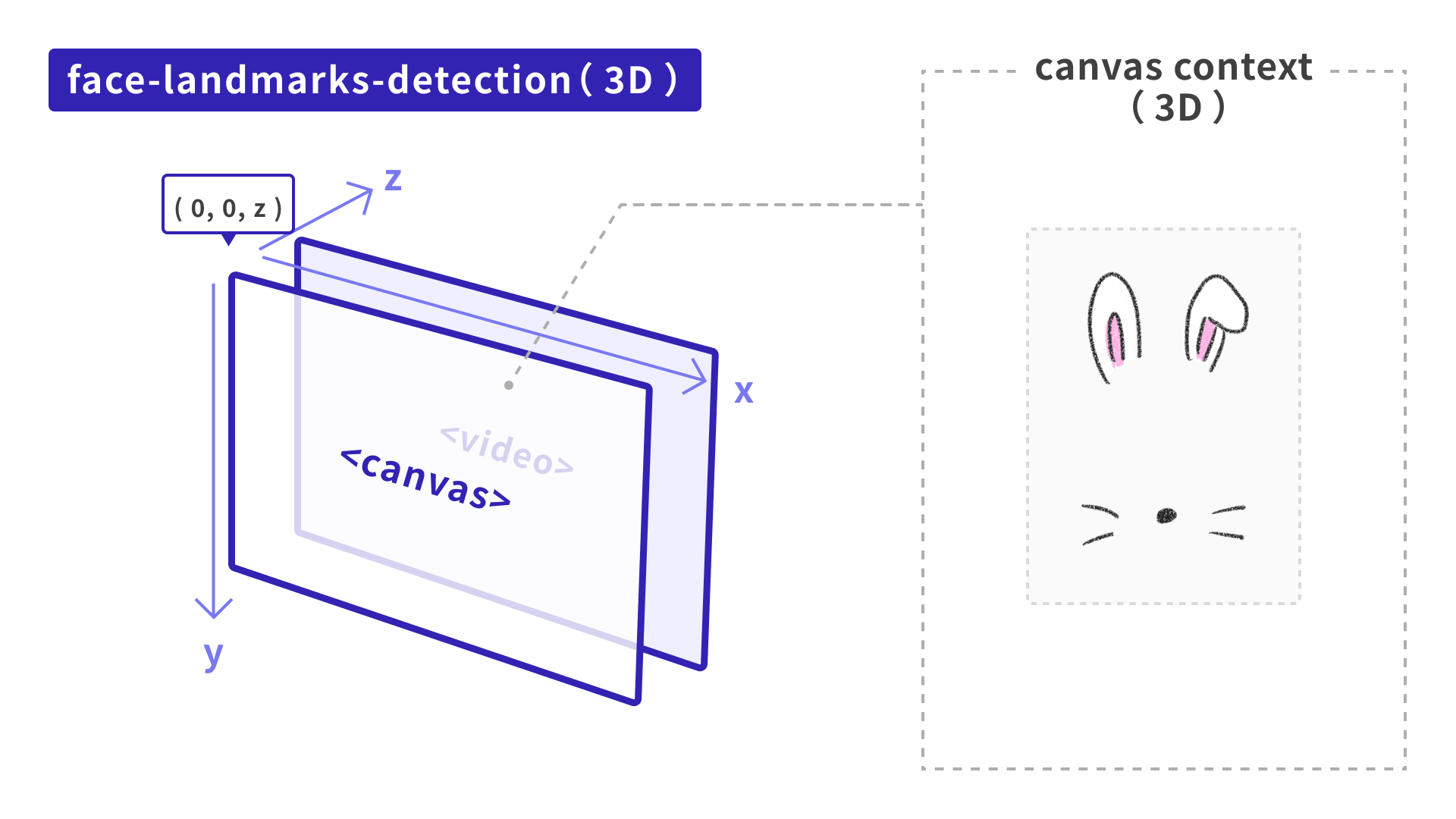
検出器から取得できるx, y, zの座標について考えます。
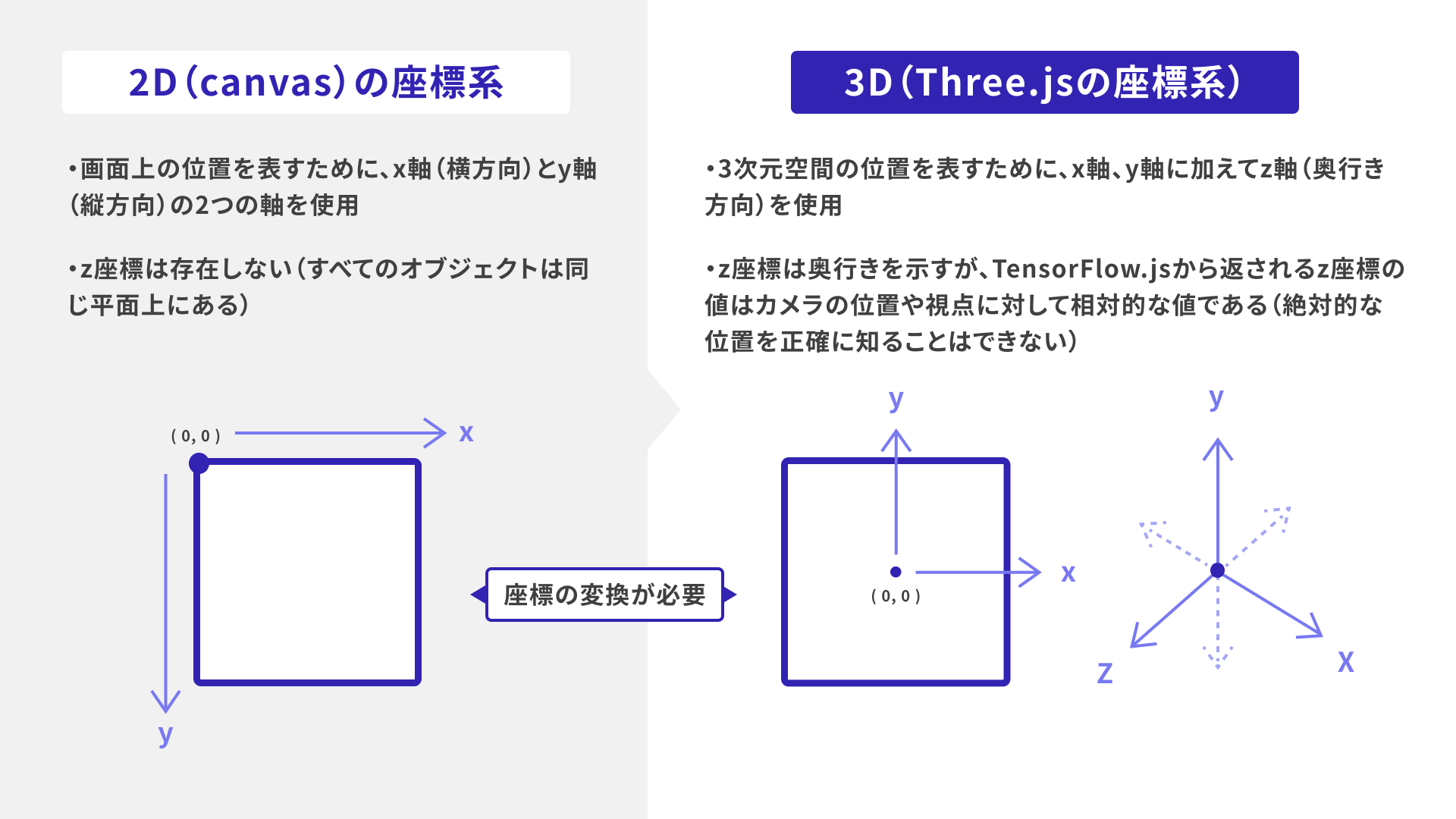
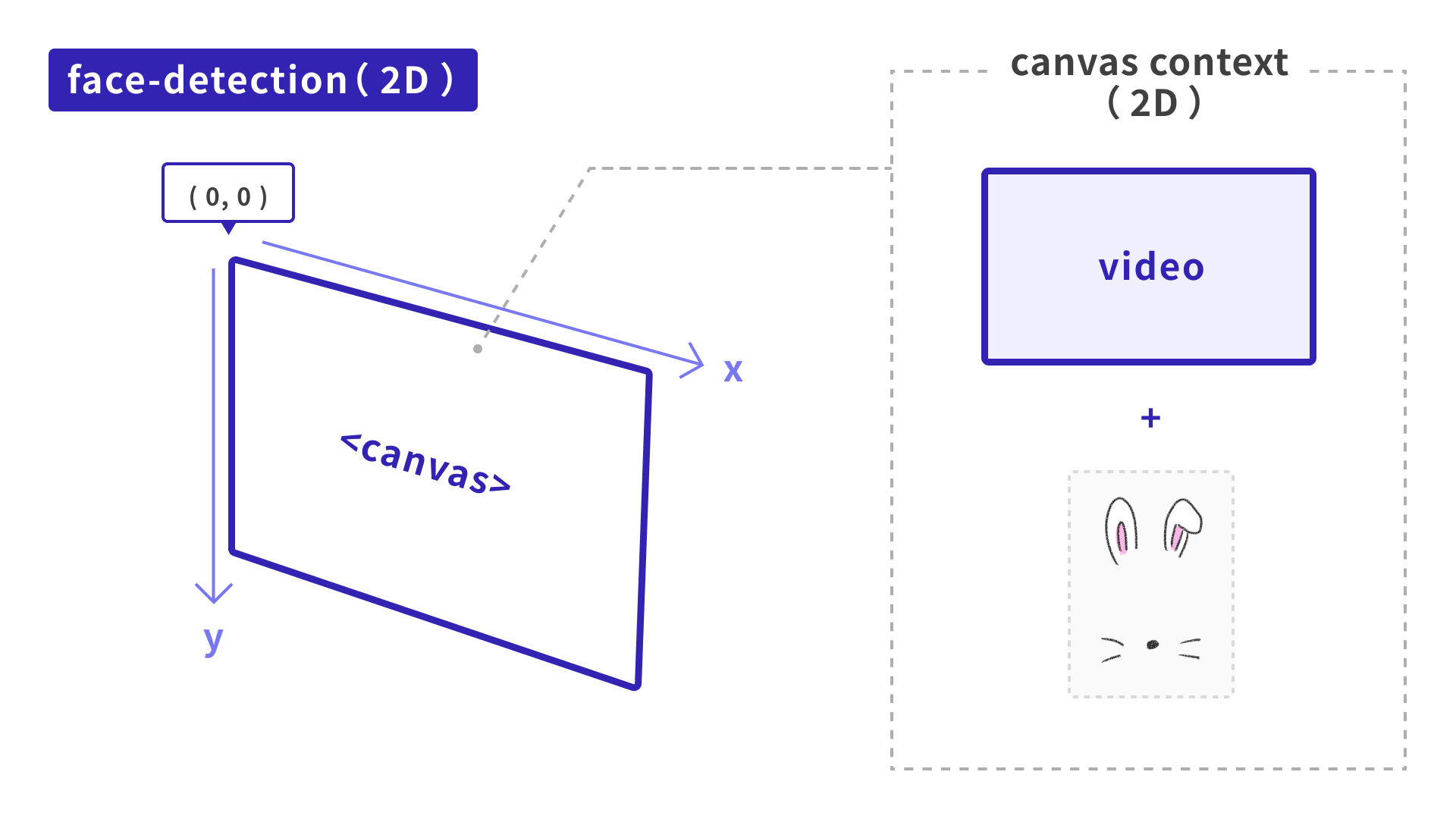
x, y座標については単純です。上の図の通り、Three.jsの座標系に合わせて2D(canvas)の座標系から変換します。
z座標は、相対的な値のままではThree.jsの3D空間上で正確に使用できないため、簡易的に自分が扱いやすい値へ変換する必要があります。今回は、以下のように計算してみます。
z: ((el.z / 100) * -1 + 1) * 100 // -50から50
さきほど「<video>タグをHTMLに配置していることが、face-detectionのデモとの違い」だと説明しましたが、理由はこのz座標の扱いにあります。取得できるz座標が正確でないため、「ウェブカメラに映っている自分の顔の位置」と「Three.jsで描画する顔の位置」を正確に合わせることが難しいのです。
そこで、次のような方法をとっています。
<video>タグと<canvas>タグを重ねて配置し、<video>タグに映っている顔の位置を基準にします。- 顔の位置に合わせて、
<canvas>上で描画される顔の位置を調整します(具体的には、Three.jsのカメラのz位置を調整することで、実際の映像とスタンプ画像が一致するようにします)。
試したところ、z座標は680の位置になりました。この数値は、自分が取得したz座標をどう使うかで変わってくるでしょう。
ポイント2:顔の傾きをどう取得するか
face-detectionのデモでは、「横を向いたとき(顔をY軸まわりに回転させたとき)に、スタンプ画像が正面を向いたままになっている」ことに違和感があると述べました。
検出器では顔の傾きを直接取得できないため、以下の方法で顔の傾きを求めます。
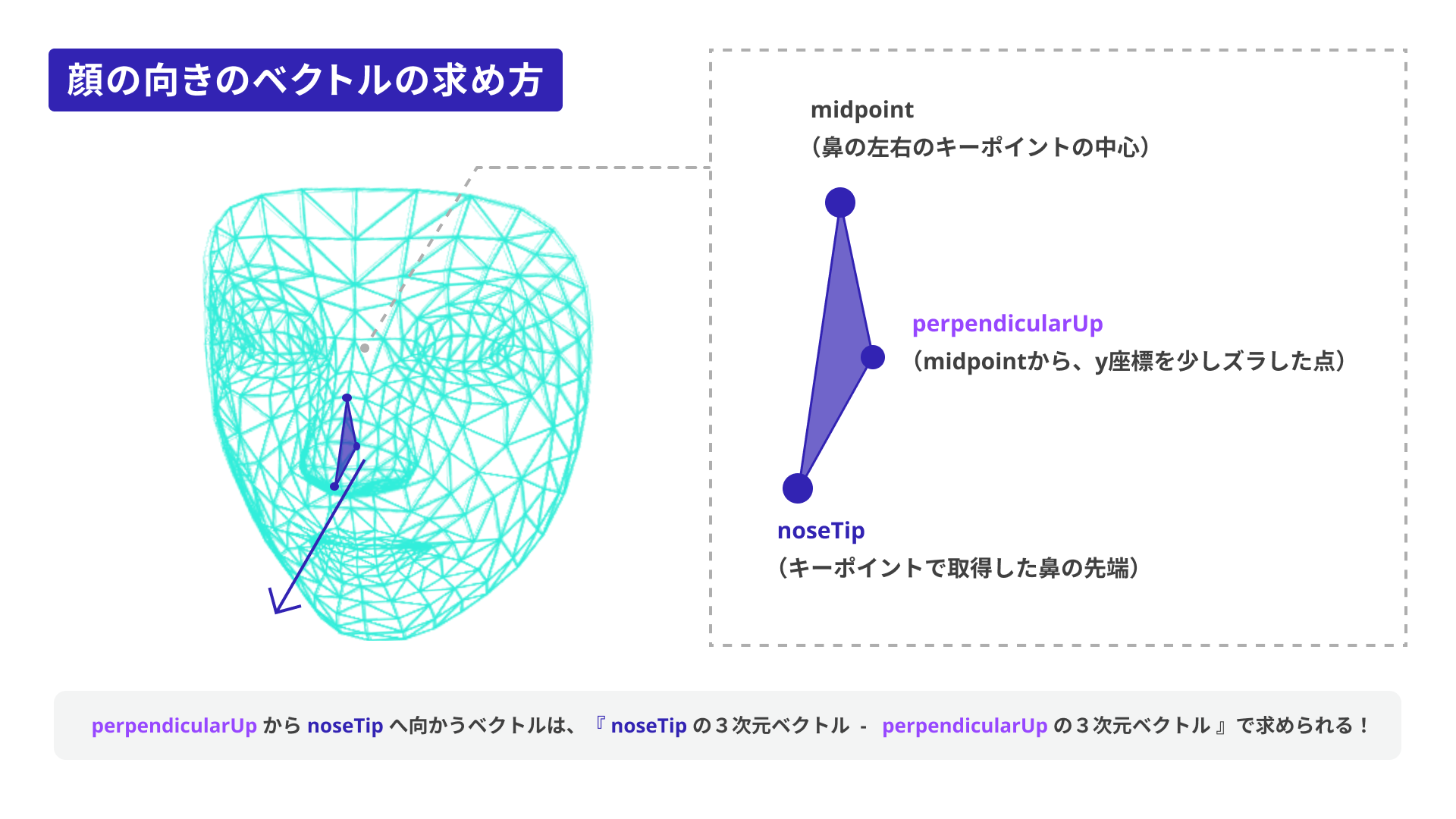
図に描かれている矢印が、顔の法線ベクトル(※)と考えられます。この法線ベクトルを平面(プレーン)に適用することで、顔の向きとスタンプ画像の向きを合わせられます。
※「法線ベクトル」とは、ある面や平面に対して垂直な方向を指すベクトルのことです。顔の法線ベクトルは、顔の面が向いている正面の方向を示します。
function calcNormalVector() {
if (!results || results.length === 0) {
return;
}
// 顔のキーポイントデータを取得し、Three.jsで使用できる座標に変換
const fixData = fixLandmarkValue(results[0].keypoints);
const noseTip = fixData[1]; // 鼻の先端のキーポイント
const leftNose = fixData[279]; // 鼻の左端のキーポイント
const rightNose = fixData[49]; // 鼻の右端のキーポイント
// 鼻の左端と右端の中間点を計算
const midpoint = {
x: (leftNose.x + rightNose.x) / 2,
y: (leftNose.y + rightNose.y) / 2,
z: (leftNose.z + rightNose.z) / 2
};
// 中間点から垂直方向に少し上の点を定義
const perpendicularUp = {
x: midpoint.x,
y: midpoint.y - 10,
z: midpoint.z
};
// 垂直方向に上の点(perpendicularUp)から鼻の先端(noseTip)までのベクトルを計算し、正規化して法線ベクトルを取得
faceNormalVector = new THREE.Vector3(noseTip.x, noseTip.y, noseTip.z)
.sub(new THREE.Vector3(perpendicularUp.x, perpendicularUp.y, perpendicularUp.z))
.normalize();
// 法線ベクトルを基にクォータニオンを作成(Z軸から法線ベクトルへの回転を表す)
const quaternion = new THREE.Quaternion();
quaternion.setFromUnitVectors(new THREE.Vector3(0, 0, 1), faceNormalVector);
return quaternion;
}
顔を傾けたり、カメラから遠ざかったり、首を回したりしてもスタンプが追従する、顔認識&フィルター機能を実装できました。
本記事のソースコードはGitHubで公開しているので、ダウンロードしてお手元でお試しください。
今回作成したデモは、スタンプ画像を差し替えたりサイズを調整したりして、ご自由に遊んでいただけると嬉しいです!
まとめ
TensorFlow.jsで実装する顔認識技術についてご紹介しました。
JavaScriptのライブラリを使った顔認識については、以前にもICS MEDIAで紹介しています。
以下のグラフは、npm trendsによるTensorFlow.jsのface-landmarks-detectionモデル、clmtrackr、ml5.jsのダウンロード数の比較です。過去にICS MEDIAで取り上げたclmtrackrやml5.jsと比べ、TensorFlow.jsのダウンロード数がもっとも多いことがわかります。
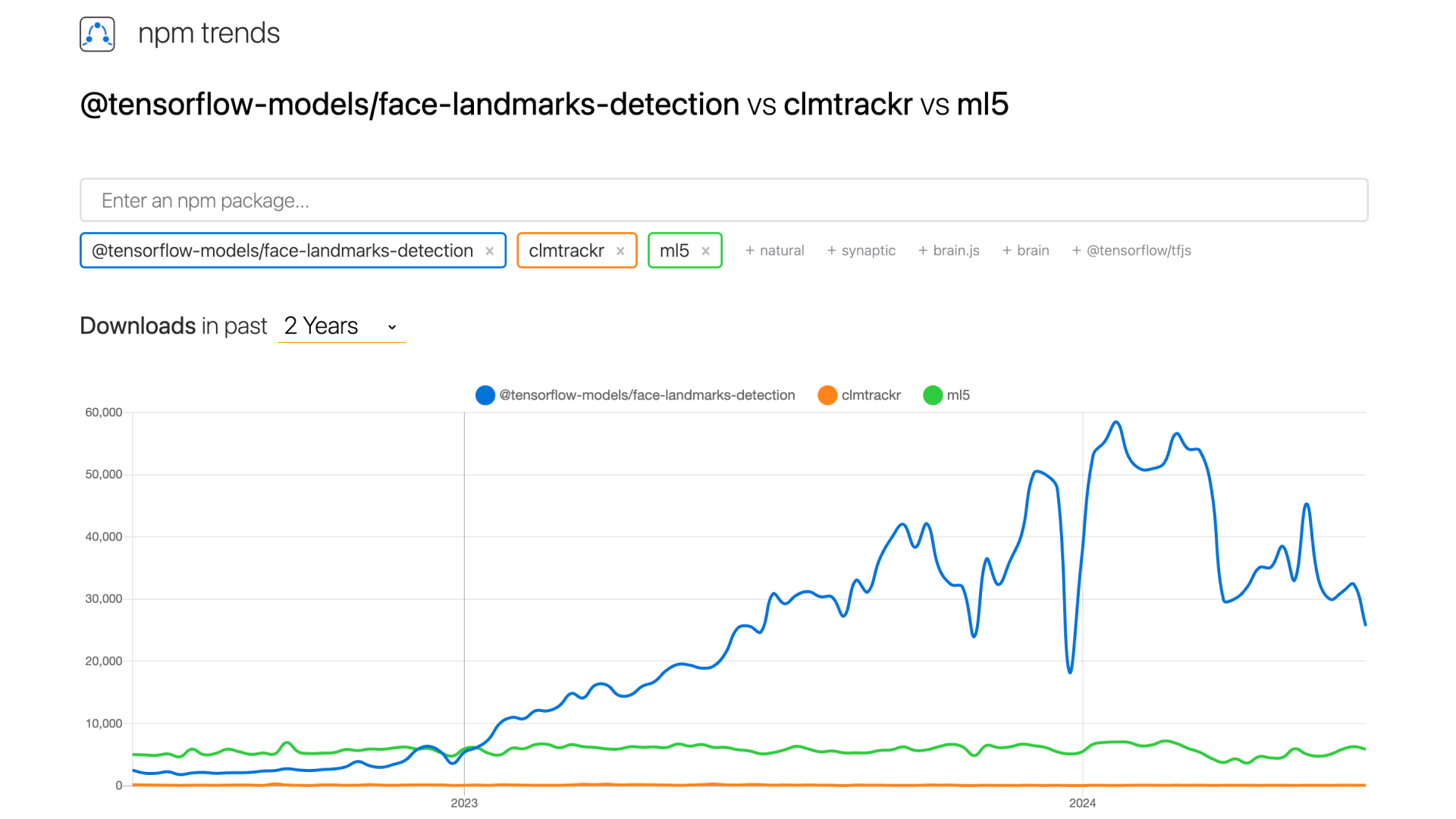
▲ 各種顔認識ツールのトレンド推移 | npm trends
前述しましたが、TensorFlow.jsには他にもさまざまなモデルが用意されています。ぜひみなさまも、これらのモデルを活用して、可愛くておもしろいウェブサイトを実装してみてください!
また、TensorFlow.jsでは事前に学習させたモデルを利用するだけでなく、自分で簡単な学習を行うことも可能です。TensorFlow.jsを利用した機械学習の方法については、次回以降の記事で詳しくご紹介したいと思います。