
前回の記事『ブラウザ上で可愛いフィルターを実現!TensorFlow.jsを使ったリアルタイム顔認識』では、Googleが開発した機械学習用JavaScriptライブラリ「TensorFlow.js」が提供する、顔認識モデルをご紹介しました。そしてウェブカメラを使用してリアルタイムで顔認識を行い、好きなスタンプ画像を選んで顔に貼り付けるデモを作成しました。
今回の記事では、TensorFlow.jsを利用し、ポーズに合わせた画像が出現するデモを作成します。
TensorFlow.jsとは
TensorFlow.jsは、Pythonで広く利用されている機械学習ライブラリ「TensorFlow」のJavaScript版です。TensorFlow.jsを利用すると、以下のようなことをブラウザ上で実現できます。
- オリジナルの機械学習モデルを作成する
- 既存の学習済みモデルを使用して再トレーニングする
- 学習済みモデルを利用する
今回の記事では、オリジナルの機械学習モデルを作成しつつ、学習済みモデル「hand-pose-detection」も利用していきます。
hand-pose-detectionとは
hand-pose-detectionモデルは、画像や動画から、人間の「手」を検出できます。公式のデモページをご覧ください。
検出結果には以下の情報が含まれます。


handedness:検出された手が右手(Right)か左手(Left)かを示す予測。score:「検出された手が右手か左手かの予測(handedness)」の信頼度を表す値。keypoints:キーポイント(2D)の配列。各キーポイントは、画像ピクセル空間における(x, y)座標と名前(name)を持つ。keypoints3D:キーポイント(3D)の配列。各キーポイントは、3次元空間における(x, y, z)座標と名前(name)を持つ。
キーポイントとは、検出された手の指の関節点です。各キーポイントには、座標と名前(手首、小指の先端など)の情報が含まれています。
このhand-pose-detectionモデルによる手検出を利用して、デモを作成していきます。
完成版デモ
画面右側のイラストのように、ピース・指ハート(親指と人差指をクロスさせてハートを作るポーズ)・ほっぺハート(片手でハートの片側を作って頬に当てるポーズ)をすると、手の位置に合わせて、それぞれ異なる画像が表示されます。
デモ作成の流れ
以下のステップで進めていきます。
- ポーズを学習させる
- ポーズに合わせた画像を描画する
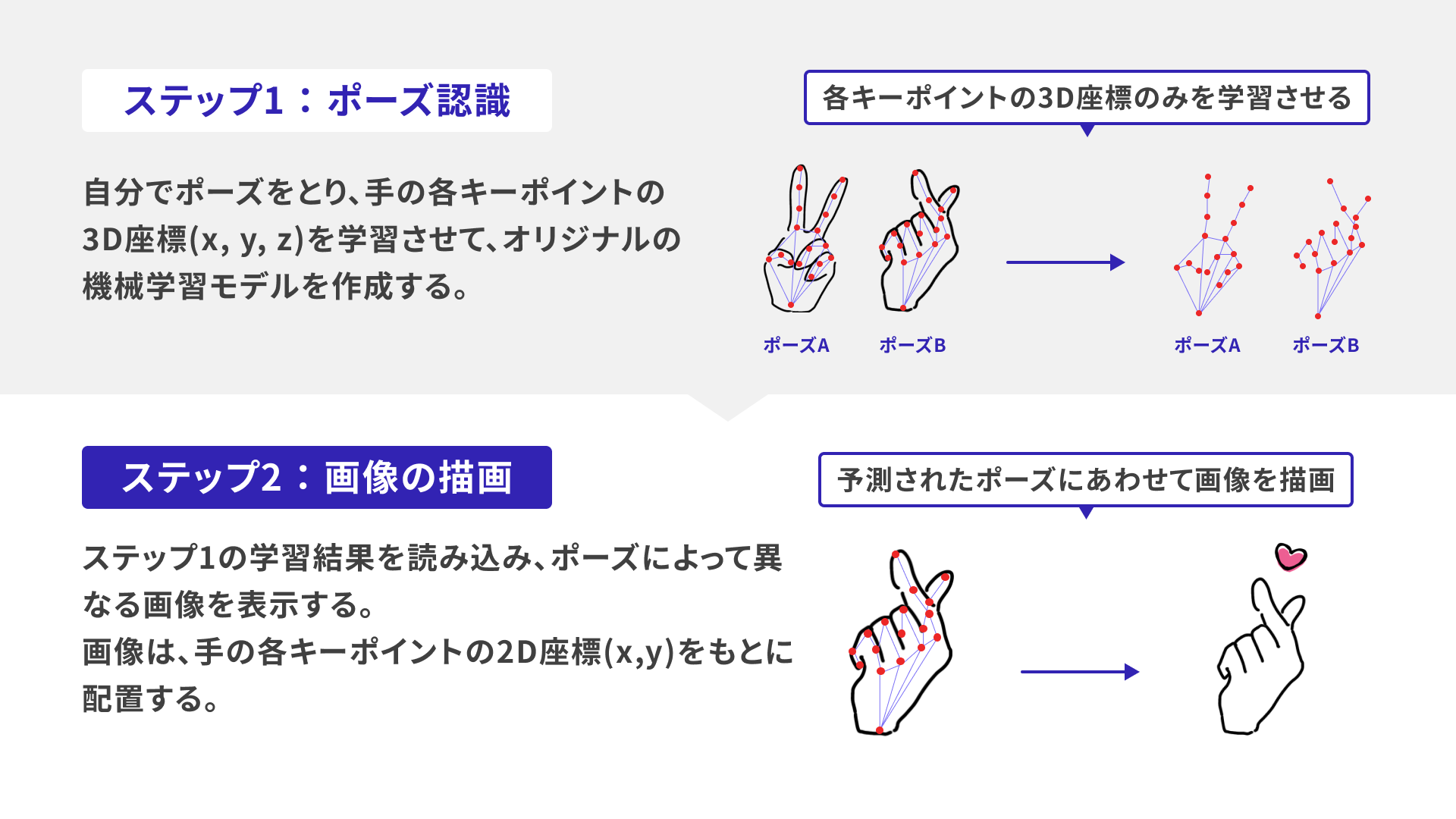
それぞれ詳しく説明していきます。
ステップ1:ポーズを学習させる
以下の動画をご覧ください。
「ポーズをとってボタンを押す」ことで、学習させるポーズを追加します。画面の「prediction」には予測されたポーズが表示され、「probability」には、その予測の確からしさが0〜1の値で示されます。
指の角度を変えたり、右手と左手をチェンジしたりして、何回かボタンを押してみてください。誤ったポーズを判定されても、正しいポーズを繰り返し学習させることで、予測を修正できます。
このデモでは、自分で新しいポーズを追加することもできます。[新しいポーズ]にテキストを入力し[追加]ボタンを押すと、新しくポーズを登録するためのボタンが作成されます。お好きなポーズを学習させてみてください!
- サンプルを別ウインドウで開く(学習過程)
- コードを確認する
それでは、簡単にデモ内での学習の流れを紹介します。
※「KNN分類器」や「テンソル」といったあまり聞き慣れない用語が登場しますが、詳細な説明は割愛しています。
1. 手の検出器を作成する
hand-pose-detectionモデルを使用し、手の検出器を作成します。
// utils.js
// 手を検出するためのhand-pose-detectionモデルを初期化する関数
export async function createHandDetector() {
// handPoseDetection はライブラリの機能
const model = handPoseDetection.SupportedModels.MediaPipeHands; // MediaPipeHandsモデルを使用
const detectorConfig = {
runtime: "mediapipe", // or "tfjs", ランタイムの選択
solutionPath: "https://cdn.jsdelivr.net/npm/@mediapipe/hands", // MediaPipeHandsのソリューションパス
modelType: "full", // モデルタイプを設定
};
// 手の検出器を作成
const detector = await handPoseDetection.createDetector(
model,
detectorConfig,
);
return detector;
}
2. KNN分類器を準備する
K近傍法(KNN)分類器を準備します。KNNは、新しいデータを既存のデータに基づいて分類する機械学習アルゴリズムです。 KNN分類器を利用することで、特定のポーズがこれまで学習したどのポーズに近いかをもとに、ポーズを予測できます。
// KNN分類器を準備する関数
function setupKNN() {
const classifier = knnClassifier.create(); // TensorFlow.jsのKNN分類器を作成
return classifier;
}
3. キーポイントの3D座標を取得する
hand-pose-detectionモデルを使って、ウェブカメラの映像から手を検出し、キーポイントを取得します。hand-pose-detectionモデルは各指の関節点の3D座標(x, y, z)をキーポイントとして取得できます(学習には片手のみを使用しています)。
// ウェブカメラの映像から手を検出する関数
async function estimateHands(detector) {
// estimateHands はライブラリの機能(手を検出する)
const hands = await detector.estimateHands(webcamElement, {
flipHorizontal: false,
});
return hands[0];
}
// 手のキーポイントの3D座標(x, y, z)を取得する関数
function getHandKeypoints3D(hand) {
if (hand) {
return hand.keypoints3D.map((point) => [point.x, point.y, point.z]);
}
return null;
}
estimateHands関数でウェブカメラの映像から手を検出します。そしてgetHandKeypoints3D関数で、検出した手のキーポイントの3D座標を取得します。手が検出されたら、座標を配列に変換します。各ポーズをとったときのキーポイントの3D座標を利用して、ポーズの判定をするためです。
4. ポーズを予測する
以下の関数では、キーポイントの3D座標をKNN分類器に渡して、ポーズの予測を行います。予測結果は画面に表示されます。
// 手のポーズを予測する関数
async function estimatePose(classifier, hand) {
if (classifier.getNumClasses() > 0) {
const keypoints3D = await getHandKeypoints3D(hand); // キーポイントの3D座標を取得
// デフォルトの予測結果は「なし」とする
let predictionText = "prediction: なし\nprobability: 1";
// 手のキーポイントの3D座標が検出された場合のみ予測を更新
if (keypoints3D) {
const tensor = flattenAndConvertToTensor(keypoints3D); // キーポイントの3D座標をフラット化しテンソルに変換
// KNN分類器を使ってポーズを予測
const result = await classifier.predictClass(tensor);
predictionText = `prediction: ${poseList[result.label]}\nprobability: ${Math.round(result.confidences[result.label] * 100) / 100}`;
tensor.dispose();
}
// 予測結果を表示
document.getElementById("console").innerText = predictionText;
}
// 次のフレームで再度処理を行う
await tf.nextFrame();
}
estimatePose関数でflattenAndConvertToTensorという関数を使用しています。「キーポイントの3D座標をフラット化し、KNN分類器が扱えるテンソル形式に変換する」ためです。
// utils.js
// 手のキーポイントの3D座標をフラット化し、テンソルに変換する関数
export function flattenAndConvertToTensor(keypoints3D) {
// キーポイントの3D座標をフラット化(1次元配列に変換)
const flattened = keypoints3D.flat();
// フラット化した配列をテンソルに変換し、2次元の形に変形
return tf.tensor(flattened).reshape([1, flattened.length]);
}
5. 学習結果をKNN分類器に追加する
ポーズを学習データとしてKNN分類器に追加します。
// ポーズの学習を追加する関数
async function addExample(classifier, classId, detector) {
const hand = await estimateHands(detector); // 手の検出結果を取得
const keypoints3D = await getHandKeypoints3D(hand); // キーポイントの3D座標を取得
if (keypoints3D) {
const tensor = flattenAndConvertToTensor(keypoints3D); // キーポイントの3D座標をフラット化しテンソルに変換
classifier.addExample(tensor, classId); // KNN分類器にポーズを追加
tensor.dispose();
}
}
引数のclassifierにはKNN分類器、classIdには追加するポーズのクラスID(どのポーズに属するかを決定するための一意の識別子)、detectorには手の検出器が渡されます。
以下のように、各ポーズのボタンをクリックすることでaddExample関数を呼び出します。ボタンが押されるごとに、「それぞれのポーズをとったときのキーポイントの3D座標が、KNN分類器に追加される」仕組みです。
// 1つ目のボタン(デモでは[ピース])
document
.getElementById("class-0")
.addEventListener("click", () => addExample(classifier, 0, detector));
// 2つ目のボタン(デモでは[指ハート])
document
.getElementById("class-1")
.addEventListener("click", () => addExample(classifier, 1, detector));
// 3つ目のボタン(デモでは[ほっぺハート])
document
.getElementById("class-2")
.addEventListener("click", () => addExample(classifier, 2, detector));
6. 学習済みのKNNモデルをダウンロードする
ポーズの学習が完了したら、モデルをテキストファイルとしてダウンロードできます。
// KNNモデルをダウンロードする関数
function downloadModel(classifier) {
// モデルのデータセットを取得し、JSON文字列に変換
const str = JSON.stringify(
Object.entries(classifier.getClassifierDataset()).map(([label, data]) => [
label,
Array.from(data.dataSync()),
data.shape,
]),
);
const blob = new Blob([str], { type: "text/plain" }); // JSON文字列をBlobとして作成
const url = URL.createObjectURL(blob); // BlobからURLを作成
// ダウンロード用のリンクを作成
const a = document.createElement("a");
a.href = url;
a.download = "knn-classifier-model.txt";
// リンクをドキュメントに追加してクリックイベントを発火
document.body.appendChild(a);
a.click();
document.body.removeChild(a); // リンクをドキュメントから削除
URL.revokeObjectURL(url); // 作成したURLを解放
}
ステップ2:ポーズに合わせた画像を描画する
このステップでは、先ほどの学習結果を利用し、予測されたポーズに基づいて画像を描画します。
- コードを確認する
以下の処理はステップ1と同様ですので、説明を割愛します。
- 手を検出するためのhand-pose-detectionモデルを初期化する
- キーポイントの3D座標をフラット化しテンソルに変換
1. 学習結果を読み込む
学習済みのKNNモデルを読み込みます。ステップ1で学習させたデータをダウンロードして利用しましょう。
以下の関数で、KNNモデルをファイルから読み込みます。
// KNNモデルを読み込む非同期関数
async function loadKNNModel() {
const response = await fetch("models/knn-classifier-model.txt");
const txt = await response.text();
const classifier = knnClassifier.create(); // TensorFlow.jsのKNN分類器を作成
// テキストをJSONとして解析し、各ラベルに対応するデータと形状を取得
// 取得したデータをテンソルに変換してKNN分類器に設定
// https://github.com/tensorflow/tfjs/issues/633
classifier.setClassifierDataset(
Object.fromEntries(
JSON.parse(txt).map(([label, data, shape]) => [
label, // ラベル(クラス名)
tf.tensor(data, shape), // データをテンソルに変換
]),
),
);
return classifier;
}
2.ポーズを予測する
ポーズを予測する関数を定義します。ウェブカメラから取得したフレームを使用し、キーポイントを取得してKNN分類器に渡します。
// 手のポーズを予測する関数
async function estimatePose(classifier, allHandKeypoints3D) {
if (classifier.getNumClasses() > 0 && allHandKeypoints3D.length > 0) {
return await Promise.all(
allHandKeypoints3D.map(async (keypoints3D) => {
const tensor = flattenAndConvertToTensor(keypoints3D); // キーポイントの3D座標をフラット化しテンソルに変換
// KNN分類器を使ってポーズを予測
const hand = await classifier.predictClass(tensor);
const classes = ["ピース", "指ハート", "ほっぺハート", "なし"]; // 各ポーズ名を取得
const probabilities = hand.confidences; // 各ポーズの確率を取得
tensor.dispose();
return {
knnResult: classes[hand.label],
knnProbability: probabilities[hand.label],
};
}),
);
}
return [{ knnResult: "なし", knnProbability: 0 }];
}
予測の流れはステップ1と同様です。予測結果は返り値としてオブジェクトに保存されます。このオブジェクトを使用して、「どのポーズでどの画像を表示させるか」を分岐させます。
3. <canvas>に画像を描画する
予測結果をもとに、「どの画像」を「指のどのあたりに画像を描画するか」をポーズごとに指定します。
// 画像を描画する関数
function drawDecoImage({ image, x, y }) {
// 省略
}
// Canvasに画像を描画する関数
function drawCanvas(hands, poses) {
if (!hands || hands.length === 0) return;
hands.forEach((hand, index) => {
const { keypoints, handedness } = hand;
const { knnResult, knnProbability } = poses[index];
// 手のキーポイントの2D座標(x, y)を名前(keypoint.name)から取得する関数
const getKeypoint = (name) =>
keypoints.find((keypoint) => keypoint.name === name);
const thumbTip = getKeypoint("thumb_tip"); // 親指の先端
const indexFingerTip = getKeypoint("index_finger_tip"); // 人差し指の先端
const middleFingerTip = getKeypoint("middle_finger_tip"); // 中指の先端
// 人差し指と中指の中間点(X座標)
const indexMiddleMidPointX = (indexFingerTip.x + middleFingerTip.x) / 2;
// 親指と人差し指の中間点(X座標)
const thumbIndexMidPointX = (thumbTip.x + indexFingerTip.x) / 2;
// 「どのポーズであるか」と「そのポーズである確率が1であるか」と「右手か左手か」で、画像と画像の貼る位置を変える
if (knnProbability !== 1) return;
if (knnResult === "ピース") {
drawDecoImage({
image: {
Right: decoLoadedImage.peace01,
Left: decoLoadedImage.peace02,
}[handedness],
x: indexMiddleMidPointX,
y: indexFingerTip.y - 30,
});
} else if (knnResult === "指ハート") {
// 省略
} else if (knnResult === "ほっぺハート") {
// 省略
}
});
}
「どのポーズであると判定されたか(knnResult)」と「その確率(knnProbability)」に応じて、対応する画像を描画します。また、検出された手が右手(Right)であるか左手(Left)であるかによって画像を変更しています。
画像を描画する位置は、検出された手のキーポイントの2D座標を基準にしています。keypoints3Dで取得できる(x, y, z)座標は3D空間での位置を示すので、<canvas>(=ウェブカメラの映像)の座標系と一致しません。そのため、画像の描画位置はkeypointsの(x, y)座標を基準にしているのです。
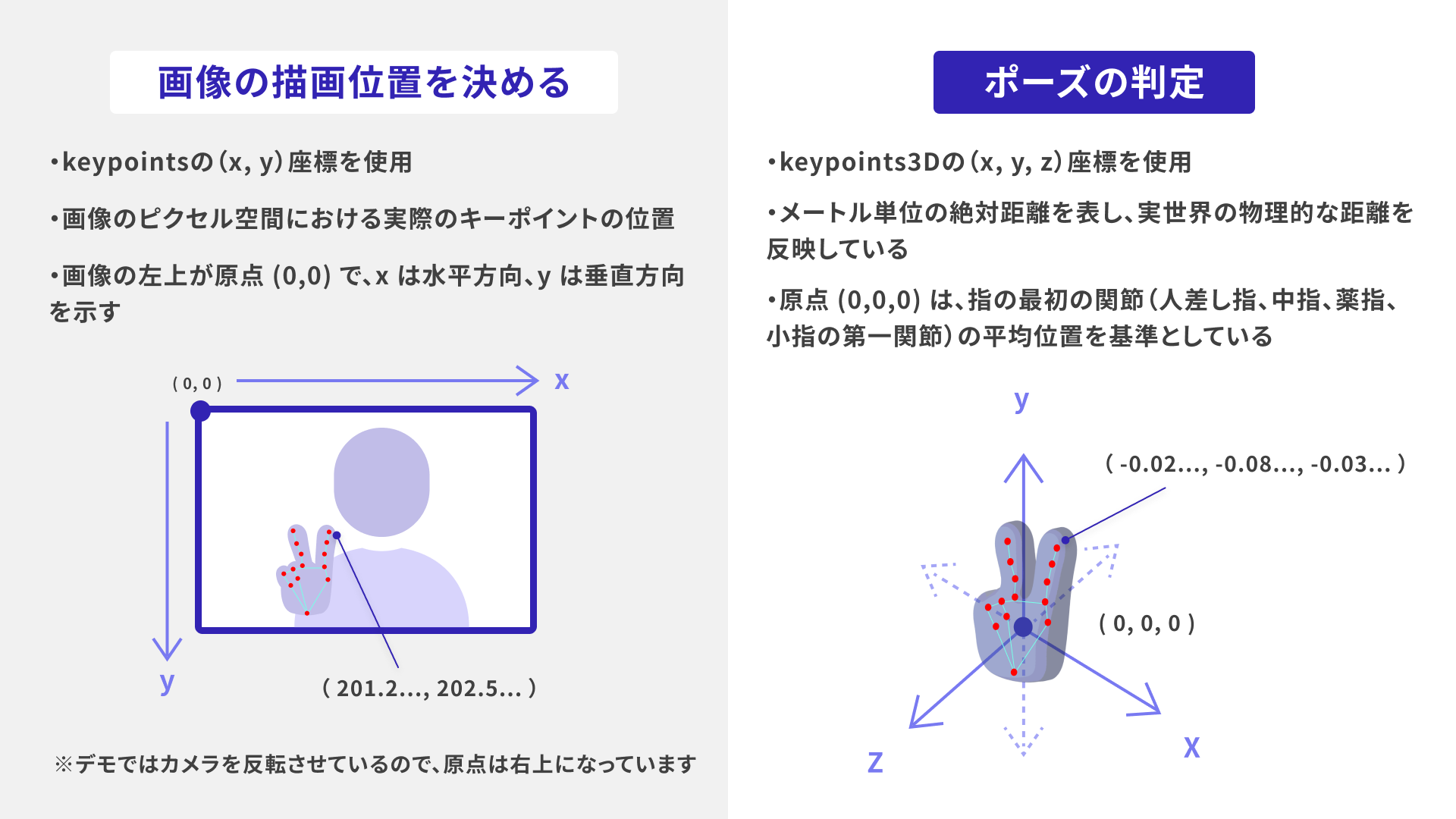
これにより、特定のポーズが認識されたとき、任意の位置に任意の画像が表示されます。
詳しい実装方法は、ソースコードをご覧ください。
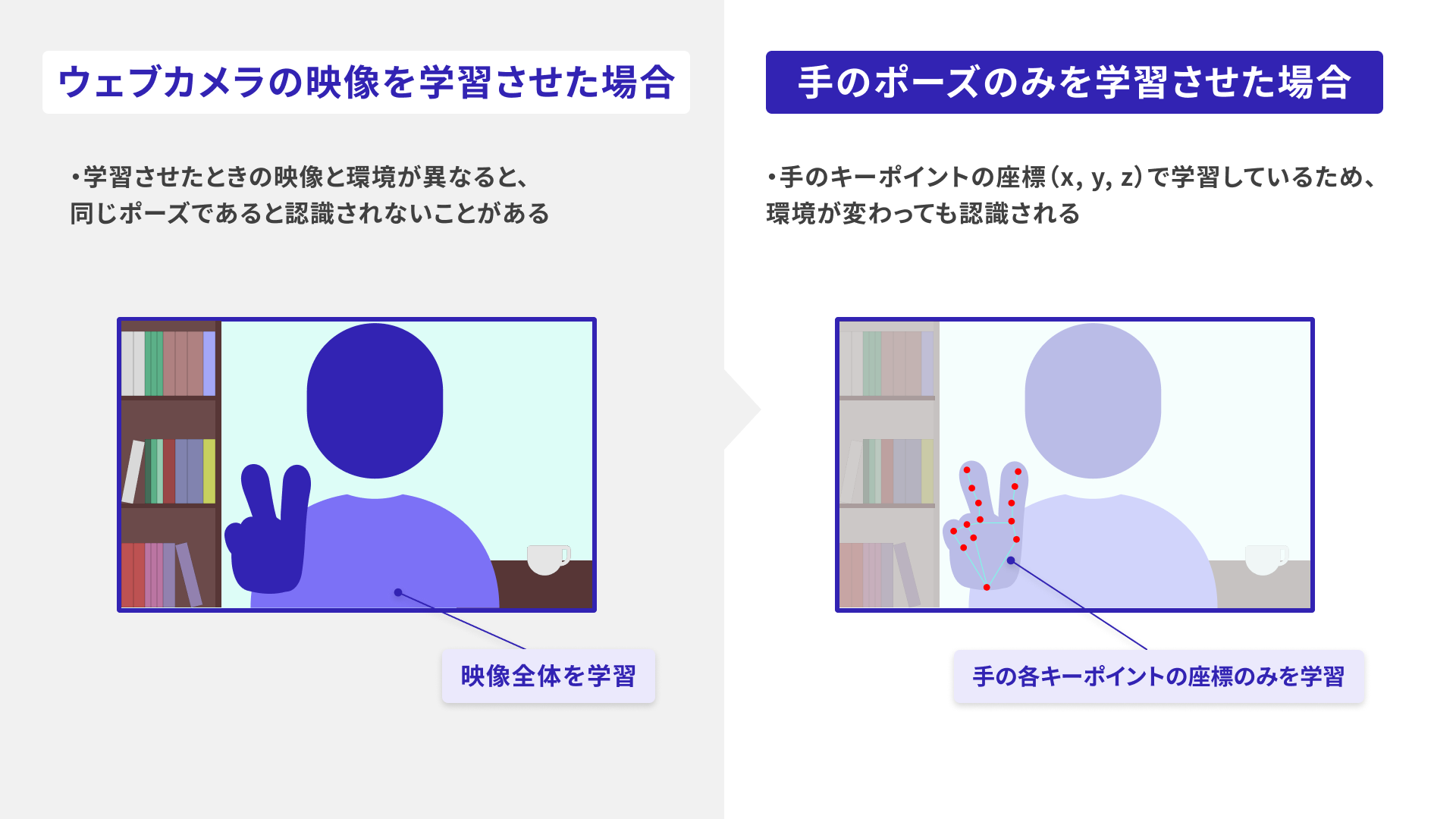
なぜ「ポーズのみ」を学習させたのか
ウェブカメラの映像をそのまま学習させることもできますが、今回は、手の検知モデル「hand-pose-detection」を利用し、手のポーズだけを学習させています。これは、背景や着ている服などの環境が変わると、予測が乱れることがあるためです。
まとめ
この記事では、以下の内容をご紹介しました。
- オリジナルの機械学習モデルの作成方法
- 学習済みモデル「hand-pose-detection」を使用してキーポイントを検出し、活用する方法
今回の記事では、オリジナルの学習済みモデルを0から作成しましたが、TensorFlow.jsでは「転移学習」という方法も利用できます。転移学習とは、すでに学習済みのモデルを再利用して新しいモデルを作成する機械学習の方法のひとつです。大量のデータを用意する必要がなく、ゼロからトレーニングするよりも少ないデータで高速にオリジナルの学習モデルを開発できます。
作成したデモのソースコードは、GitHubで公開しています。ぜひお手元にダウンロードしていただき、お好きなポーズで再学習させたり、画像を差し替えたりして遊んでみてください!
