
ユーザーエージェント文字列は、ユーザー分析やデバイス・ブラウザーで処理を分けたい時に広く用いられています。取得方法は昔からあまり変わっておらず、ウェブブラウザーの種類・バージョン・プラットフォームごとに固有の文字列を取得しています。
実は、この文字列が固定化され、正常に情報を取得できなくなっていることをご存知でしょうか?
今回はユーザーエージェント文字列の変遷を追いながら、現在策定されている新しいユーザーエージェント仕様である「User-Agent Client Hints」の概要を紹介します。
User-Agent Client Hintsの使い方、ユーザーエージェント文字列が固定化された時の対応についてもまとめています。
旧来のユーザーエージェント判別方法
従来のユーザーエージェント文字列取得は、navigatorオブジェクトのuserAgentプロパティを参照する方法です。
const ua = navigator.userAgent;
// 以下はmacOS Catalina Google Chrome 83でユーザーエージェント文字列を取得した場合の例です。
// "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5)
// AppleWebKit/537.36 (KHTML, like Gecko)
// Chrome/83.0.4103.116 Safari/537.36"
この文字列にはユーザーのデバイス・使用ブラウザーなどさまざまな情報が含まれており、ここから必要な情報を抽出することでブラウザーごとの処理を分けられます。
ユーザーエージェント文字列の意味
ユーザーエージェント文字列は、取得してきた文字列からデバイス・ブラウザーを特定できるユニークな部分をJavaScriptのincludes()やindexOf()メソッドなどで絞り込んで判別するのが一般的です。
みなさんはユーザーエージェント文字列がなぜこのような複雑な形式になったのかご存知でしょうか? 実は、ユーザーエージェント文字列のフォーマットは厳密に決まっていません。現在では、Mozillaが定めた文字列仕様にしたがっているブラウザーが多いようです。
User-Agent: Mozilla/<バージョン情報> (<システム情報>) <プラットフォーム情報> (<プラットフォーム詳細情報>) <その他の情報>
たとえば冒頭で表示したmacOS Catalina / Google Chrome 83でのユーザーエージェント文字列は以下のような意味を持っています。

「Mozilla/<バージョン情報>」の部分は形骸化しているため昨今のウェブブラウザーにおいては意味をなしませんが、ほぼすべてのブラウザーに付与される共通トークンとなっています。
ユーザーエージェント文字列の歴史とブラウザー戦争
ユーザーエージェント文字列は長いブラウザー戦争による変遷があり、今の形に落ち着いています。
1993年に登場した最古のウェブブラウザーである「NCSA Mosaic」の時点で、すでにユーザーエージェント文字列は実装されていました。他に競合となるブラウザーが登場していなかったこともあり、当時のユーザーエージェント文字列は「製品識別子/製品バージョン」のみの非常にシンプルなものでした。
Mosaic/0.9
1994年には、「Mozilla」というブラウザーが誕生しました。「Mozilla」の名前の由来に対してトラブルがあり、ブラウザーの名前を「Netscape」に変更されました。このとき、Netscapeのユーザーエージェント文字列に「Mozilla」が残り続けました。
NetscapeはこのほかにもOSや暗号化タイプの情報などをユーザーエージェント文字列に追加しました。
Mozilla/Version [Language] (Platform; Encryption)
Mozilla/2.02 [fr] (WinNT; I)
Netscapeは「フレーム」というNSCA Mosaicにはない機能を持っていました。NSCA MosaicとNetscapeというふたつのブラウザーで機能の差異があらわれ、ここでウェブ開発者たちによってユーザーエージェント文字列識別による処理分岐がおこなわれるようになりました。
Microsoftが1995年にInternet Explorerをリリースしました。当時は「MozillaかMosaicか?」という製品名でユーザーエージェント判定を行っていたため、独自のプロダクト名をユーザーエージェント文字列に付与すると、本来は正常に表示できる機能をブラウザー側で備えているにもかかわらずInternet Explorerでページを表示できなくなる危険性がありました。
そのため、Internet ExplorerはNetscapeのユーザーエージェント文字列と互換性のある「Mozilla」をユーザーエージェント文字列に付与しました。
Mozilla/2.0 (compatible; MSIE 3.02; Windows 95)
ブラウザーの製品情報はユーザーエージェント文字列のコメント部分へ記載するようにし、「Mozilla」の互換性を優先した形です。Internet ExplorerがNetscapeとのブラウザーシェア争いに勝利したあとも、この「Mozilla/バージョン番号」というフォーマットは他のブラウザーに受け継がれていきました。
ユーザーエージェント・スニッフィング
前述のように特定のブラウザーを優遇するためにユーザーエージェント文字列を利用して機能の制限やアクセス可否の判定を行うことは、「ユーザーエージェント・スニッフィング」と呼ばれています。本来は正常に表示できる機能をブラウザー側で備えているにもかかわらず、ユーザーエージェント文字列でヒットしないがゆえにウェブサーバー側でブロックされてしまうという理不尽な現象が発生します。
現在では後述の方法で回避されていますが、Operaを前身にもつブラウザーである「Vivaldi」がユーザーエージェント文字列判別を使ってサイト利用を制限されてしまっていた経験を持っています。
ユーザーエージェントの偽造
近年にもユーザーエージェント判定をめぐる問題は起こっています。有名なものだと、上述のウェブブラウザー「Vivaldi」がサービスからのアクセス拒否を防ぐため、やむなくユーザーエージェント文字列をGoogle Chromeに偽装するといった事例があります。
プライバシー問題
ユーザーの個人特定を避けるため、AppleがサードパーティのCookieを排除するようになったのは有名な話です。実はブラウザー特定に利用しているUA文字列も個人特定の判断材料に悪用されてしまうケースがあります。ユーザーエージェント文字列は、ウェブブラウザーでサイトにアクセスした際HTTPヘッダーから送信される情報の一部に含まれています。
HTTPヘッダーの情報を用いてユーザーを追跡する手法は「ブラウザー・フィンガープリント」と呼ばれています。本来は不正アクセス時の証拠ログとして活用されるべき技術なのですが、ユーザー追跡のためにも使用できてしまいます。
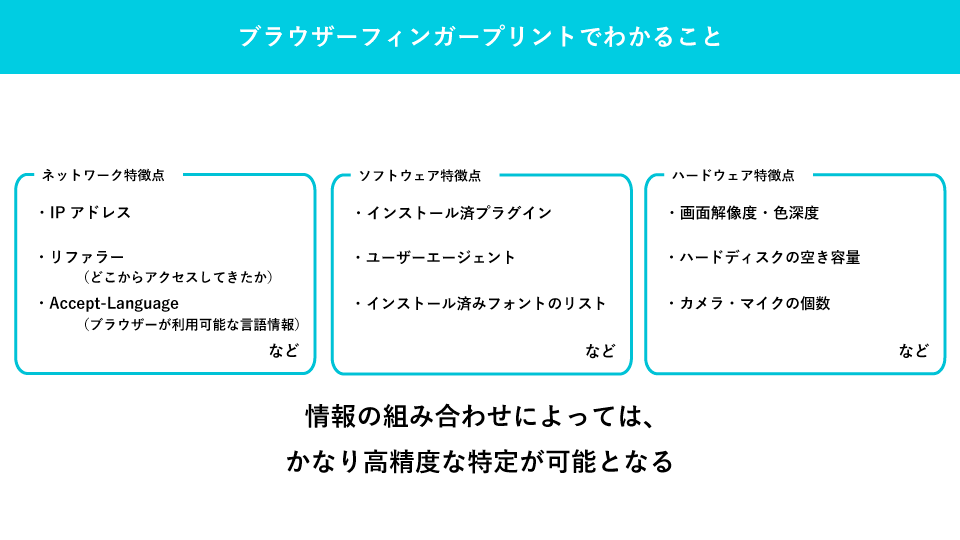
ユーザーエージェント文字列の固定化・削減化
W3CのコミュニティグループのひとつであるWICG(Web Platform Incubator Community Group)は、こうしたブラウザーの不毛なシェア争いやユーザーのプライバシー保護の解決のため、ユーザーエージェント文字列の固定化・凍結させることで重要性を低くし、情報の公開度を限定化させる方針としています。
2020年9月には、Google Chromeでは本格的にユーザーエージェント文字列の凍結を施策実施予定でしたが、COVID-19の影響により2021年に延期となりました。
参照:Intent to Deprecate and Freeze: The User-Agent string
その後、ユーザーエージェント文字列は凍結ではなく削減に動き出します。2021年9月に削減計画とそれにともなうトライアルの情報がアナウンスされました。この計画に沿う形で、Chrome 101ではマイナーバージョンの固定化、Chrome 107ではデスクトップ向けのユーザーエージェント文字列が完全に削減、Chrome 110ではAndroidのモバイルとタブレット向けのユーザーエージェント文字列が完全に削減されました。
参照:User-Agent Reduction Proposed Timeline
2025年6月にリリースのAndroid 16では、WebViewのユーザーエージェントの文字列削減されています。
参照:Android WebView でのユーザー エージェント文字列削減
さまざまな段階を経て行われた文字列の削減ですが、現在は以下のページで詳細を確認できます。
2026年現在、ユーザーエージェント文字列では、OSのバージョン情報が固定化されていたり、ブラウザのバージョン情報も正確に取得できません。次のような弊害があります。
- Windowsのバージョンは10で固定化されている(Windows 11と区別できない)
- macOSのバージョンが10.5.7で固定化されている(macOSのバージョンが判断できない)
- iOSのバージョンも18.7で固定化されている(iOSのバージョンが判断できない)
- macOSとiPadOSの区別ができない
ユーザーエージェント文字列を元データとしたアクセス解析では、これらの情報を正しく集計できません。Google Analytics 4の集計結果ですら正確ではありません。
新しいユーザーエージェント判別方法:User-Agent Client Hints
User-Agent Client Hints(UA-CH) とは、上記の問題を解決するための仕様です。
User-Agent Client HintsはJavaScriptのnavigator.userAgentDataオブジェクトでデータを参照できるようになります。
Google ChromeとEdgeがUser-Agent Client Hints APIに対応しているので、実際に試してみましょう。Chrome・Edge 90以上(2021年4月リリース)で利用できます。SafariとFirefoxは未対応です。
navigatorオブジェクトに新しく追加されているuserAgentDataを参照します。
const ua = navigator.userAgentData;
上記のコードをコンソールで実行すると、NavigatorUADataというデータ情報が返ってきます。
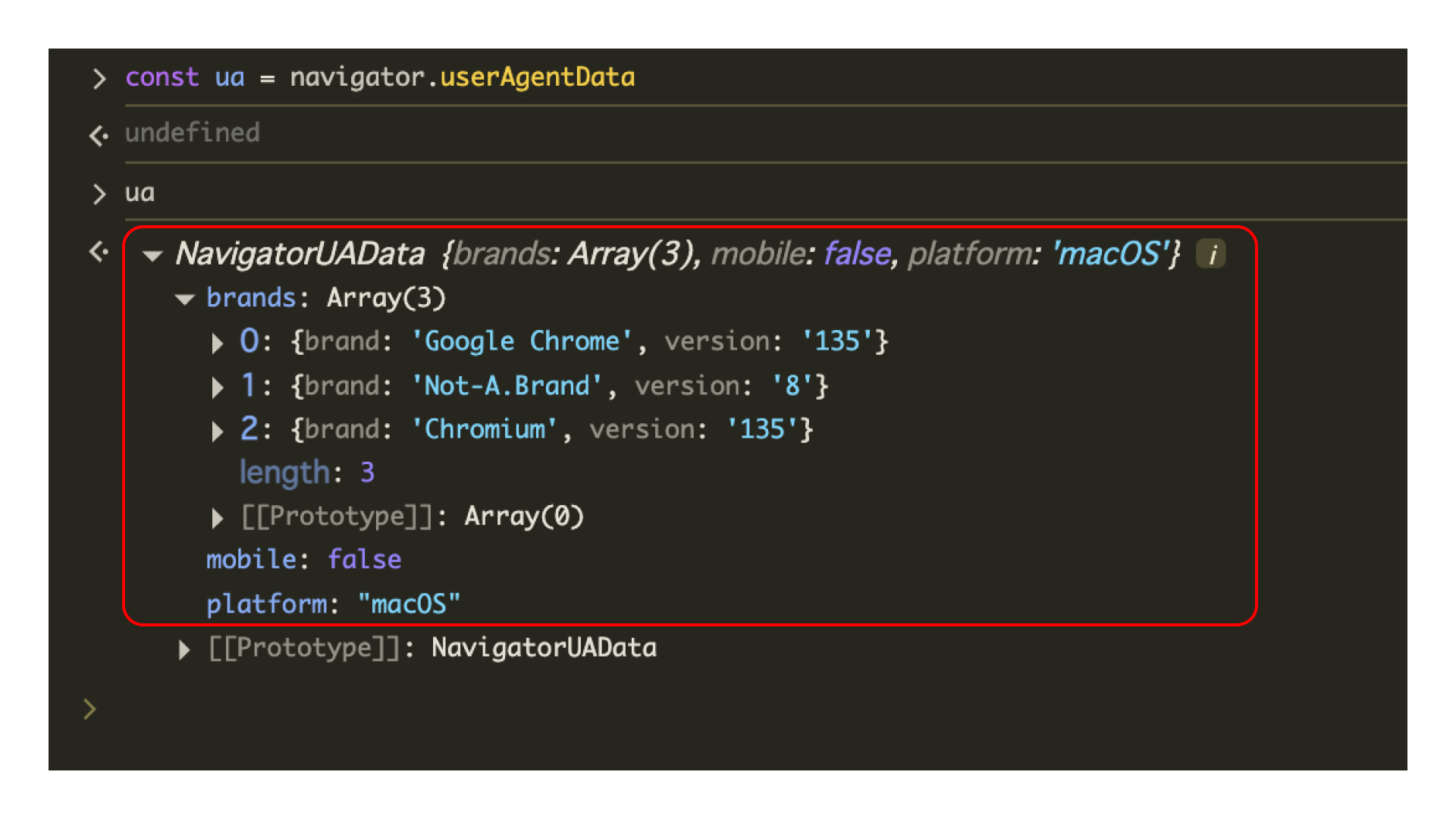
brands配列の中に複数のオブジェクトが格納されています。User-Agent Client Hintsが次の仕様を持つためです。
- ランダムにブランド情報を並べ替える
- ユーザーエージェント・スニッフィングを避けるため、ダミーの値を格納する
navigator.userAgentDataには、以下の情報が返却されます。
| プロパティー | 返却される内容 |
|---|---|
brands |
ブラウザーの種類・バージョン情報が格納された配列 |
mobile |
モバイル端末で閲覧しているかどうか? |
platform |
ユーザーエージェントが動作しているプラットフォームのブランド情報 |
brands配列にbrand、versionというプロパティの入ったオブジェクトが格納されています。brandは使用しているブラウザーの種類を、versionはブラウザーのバージョンを示しています。また、NavigatorUAData.mobileプロパティには「現在モバイル端末で閲覧しているか?」という情報が真偽値で返却されるようになっているため、とてもわかりやすくなっています。
サーバーへのリクエスト値にも新しい値が増えています。User-Agent Client Hintsを有効にした状態でウェブページを閲覧し、以下の操作を行ってみましょう。
Google Chromeのデベロッパーツールを開き、「Network」タブを選択します。その後、「Doc」を選択し、「Headers」を確認するとsec-ch-ua、sec-ch-ua-mobileというプロパティーがリクエストヘッダーにあることがわかります。
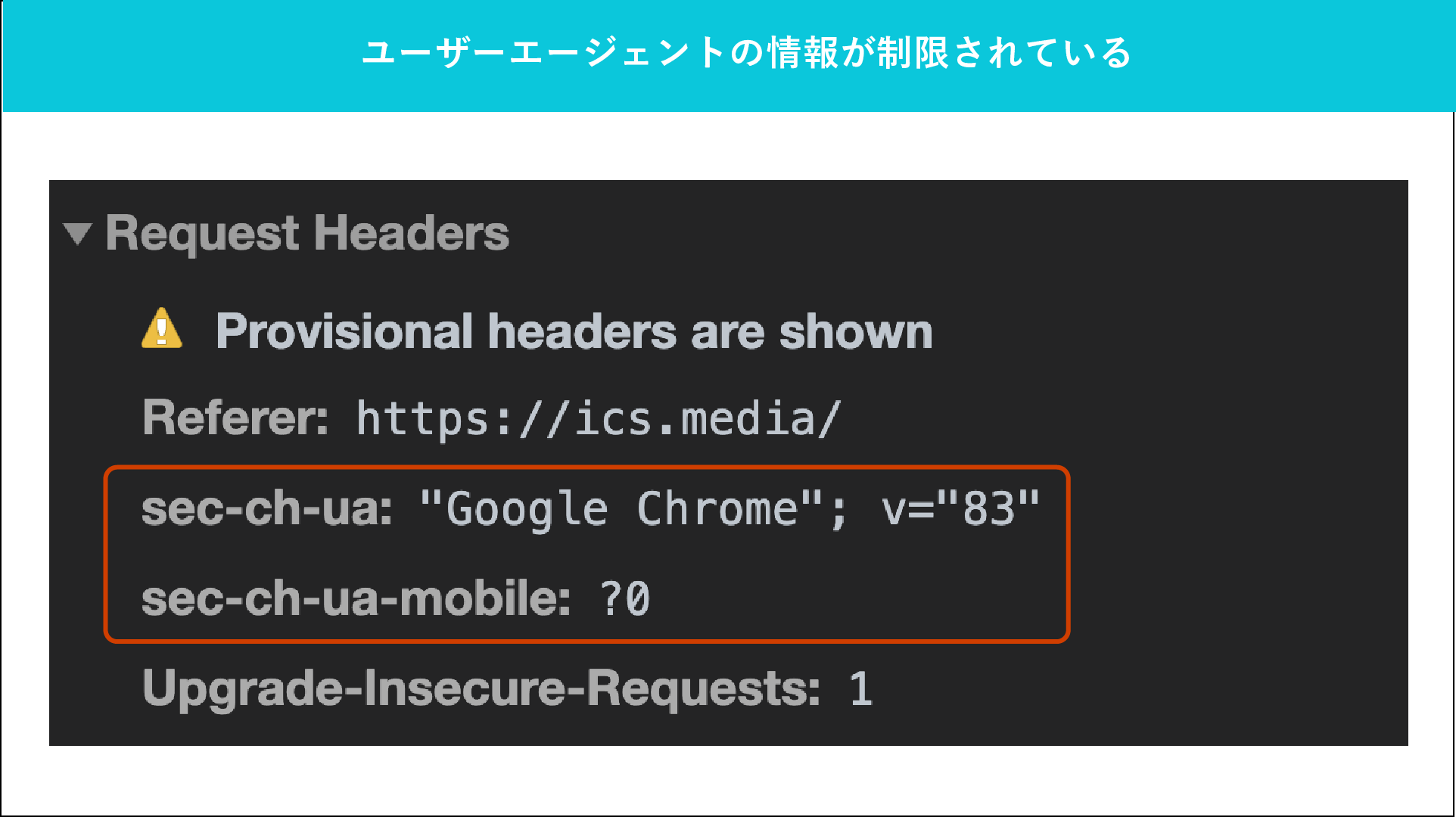
User-Agent Client Hintsの仕様ではサーバー側がAccept-CHというヘッダーを付与して情報を要求しない限り、リクエスト側が送る情報を制限するようにしているため、このようなプロパティーが追加されています。
さらに詳細な情報を取得したい場合は、getHighEntropyValues()メソッドを実行します。この関数はPromiseを返却するため、非同期での実行が必要となります。
const uaData = navigator.userAgentData;
// getHighEntropyValues()メソッドには、
// 取得したい情報を配列の引数で渡す必要があります。
const highEntropyValues = await uaData.getHighEntropyValues(
[
"platform",
"platformVersion",
"architecture",
"model",
"fullVersionList"
]);
// OS情報。"Mac OS X"など
const platform = highEntropyValues.platform;
// OSバージョン情報。"10_15_4"など
const platformVersion = highEntropyValues.platformVersion;
// CPUアーキテクチャ情報。"x86", "arm"など
const architecture = highEntropyValues.architecture;
// デバイスモデル。"Pixel 2 XL"など
const model = highEntropyValues.model;
// ブラウザーのビルドバージョン。"84.0.4113.0"など
const fullVersionList = highEntropyValues.fullVersionList;
// ログに出力
console.log({ platform, platformVersion, architecture, model, fullVersionList });
ユーザーエージェント文字列固定化への対応
ユーザーエージェント文字列が固定化されているので、既存のシステムに対して対応が必要な場合も出てきます。既存のユーザーエージェント判定処理に分岐対応を加え、User-Agent Client Hints APIが使用できるようであればそちらを使用するように修正します。
// User-Agent Client Hintsが利用できるようであれば
if (window.navigator.userAgentData) {
// ブランド情報を取得
const brands = navigator.userAgentData.brands;
// User-Agent Client Hintsのブランド情報には
// ユーザーエージェント・スニッフィング回避目的のダミーデータも含まれているため、
// 必要な情報を抽出する。
// 下記では、Google Chromeであるかどうかを判別している
const browserName = "Chrome";
const brand = brands.find(item => item.brand.includes(browserName)).brand;
...
} else {
// 既存のユーザーエージェント判定処理
...
}
ユーザーエージェント文字列によって処理を分岐させるようなシステムは実はあまり望ましくありません。そのため、本来はユーザーエージェントでの処理分岐で実装されている部分を見直し、可能であればブラウザーが使用したい機能のAPIをサポートしているかどうかで判別するように改修するのがいいでしょう。
User-Agent Client Hintsのメリット
プライバシー性の強化
現在ではユーザーがウェブサイトにアクセスした時点で、リクエストヘッダーにユーザーエージェント文字列は付与されています。User-Agent Client Hintsの仕様では、上述の通りリクエスト側からのユーザーエージェント情報は制限されたものになります。詳細な情報を取得するためにはサーバー側でAccept-CHヘッダーを付与する必要がありますが、これも同一オリジン内のエンドポイントでしか有効になりません。そのため、レンダリングエンジンやOSプラットフォーム情報といったユーザー追跡のヒントになりうる情報は漏洩しにくくなります。
必要な情報だけをコンパクトに取得できる
ウェブサイトの制作者側にもメリットがあります。ひとつの文字列としてではなく、情報が細分化されてオブジェクトのプロパティ化して返却されるため、必要な情報だけをスマートに取得できるようになります。「Mozilla/5.0」、「Gecko」といった不要な情報を取得する必要もないので、ムダのないコードを書けます。また、モバイル判定についてもnavigator.userAgentDataで返却される情報の中に値が含まれているため、クライアント側での判別は比較的容易になります。
おわりに
昨今のウェブサービスはユーザーのプライバシー情報に関して非常に敏感です。ユーザーエージェント文字列はプライバシー面での問題もありましたが、ブラウザー同士のシェア争いに使われ、偽造された挙句ついには削減の方針になってしまいました。
User-Agent Client Hintsは便利ですが、SafariとFirefoxで使えないのが痛手です。その経緯と新しいユーザーエージェントの方針についてしっかりと把握しておき、マイグレーション対応の際あわてないようにしましょう。
※この記事が公開されたのは6年前ですが、半年前の1月に内容をメンテナンスしています。
