
JavaScriptのSetを使っていますか? 多用はしていなくても[...new Set(array)]で配列の重複をなくしたり、set.has()で存在チェックを行うコードはきっと見たことがあるはずです。
2025年6月に正式仕様がリリースされるES2025で、このSetをさらに便利にする「集合演算」の新しいメソッドが追加されました。2024年にBaseline(2024 Newly available)になっており、すでに主要ブラウザーすべてで利用可能です。
この記事では新しく追加されたメソッドをよくある利用例とともに紹介します。今まで配列のforEachやfilterを多用していたような処理がより簡潔に書けるようになるだけでなく、コードの意図が明確になり、読みやすさや保守性も向上します。
Setの新機能
新機能の説明の前に、Setの基本を確認しておきましょう。すでにご存知の方は読み飛ばしてください。
Setの基本的な使い方
Setは、重複を許さないデータの集合を表すデータ型です。配列と似ていますが、同じ値は何回追加しても1つだけになります。
const fruits = new Set(); // 空のSetを作成
fruits.add("🍎りんご");
fruits.add("🍊みかん");
fruits.add("🍌バナナ");
fruits.add("🍎りんご");
console.log(fruits); // Set { "🍎りんご", "🍊みかん", "🍌バナナ" }
// ... 重複したりんごは1つだけになる
Setは配列と簡単に変換できます。
// 配列からSetを作成
const fruitsSet = new Set(["🍎りんご", "🍊みかん", "🍌バナナ"]);
// Setから配列を作成
const fruitsArray = Array.from(fruitsSet);
console.log(fruitsArray); // [ "🍎りんご", "🍊みかん", "🍌バナナ" ]
配列とSetを相互に変換した際は、(重複した要素を除いて)元の順序が維持されます。
Setの新しい集合演算
ES2025で追加された新しい集合演算のメソッドは以下の通りです。
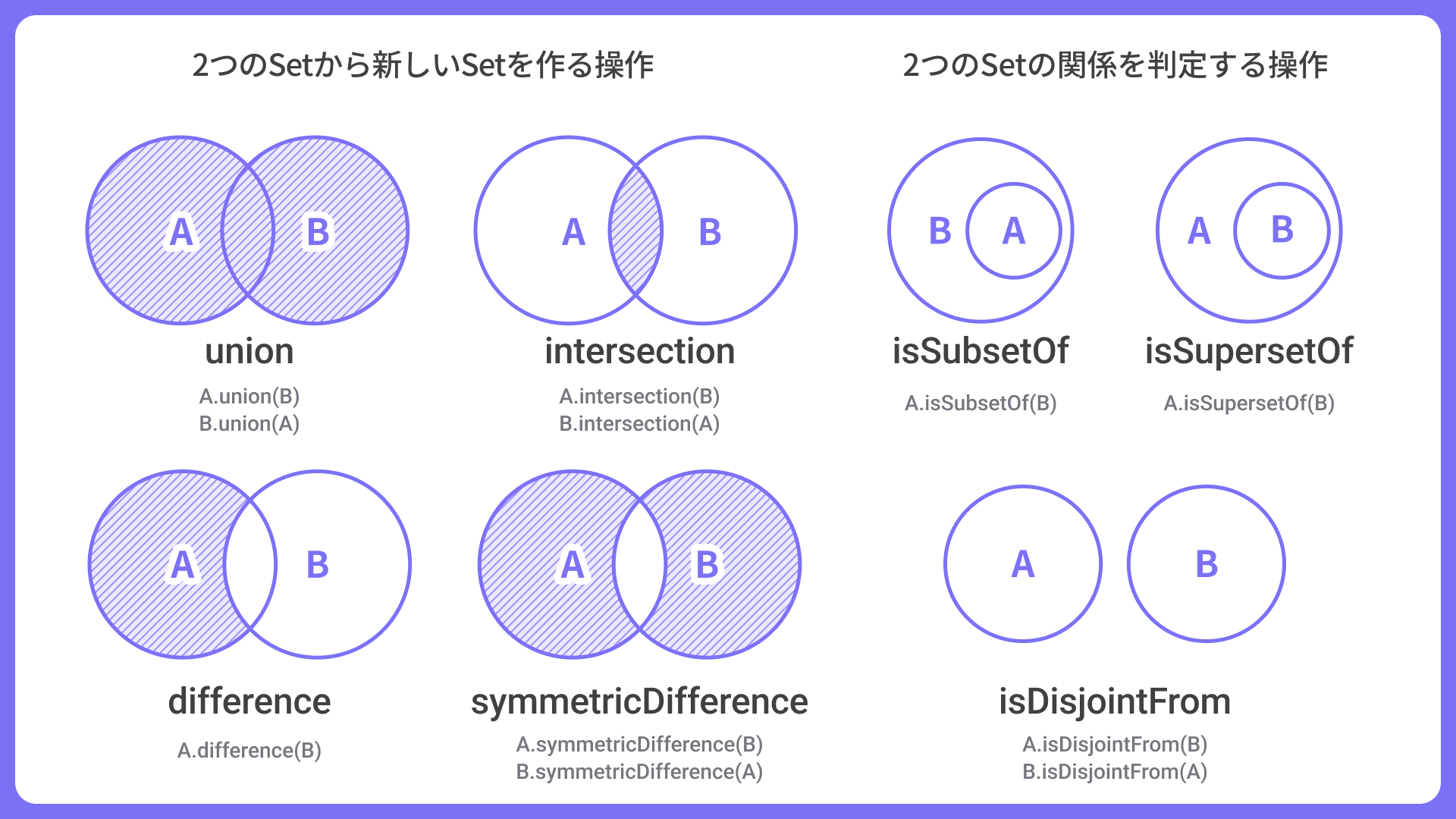
2つのSet(setAとsetB)から新しいSetを作成するメソッド(戻り値はSet):
setA.union(setB):和集合を返す(setAとsetBの要素をすべて含むSet)setA.intersection(setB):積集合を返す(setAとsetBの共通要素のSet)setA.difference(setB):差集合を返す(setAからsetBの要素を除いたSet)setA.symmetricDifference(setB):対称差集合を返す(setAとsetBの片方だけに含まれる要素のSet)
2つのSet(setAとsetB)の関係を判定するメソッド(戻り値はboolean):
setA.isSubsetOf(setB):部分集合かどうかを返す(setAがsetBに含まれるか?)setA.isSupersetOf(setB):超集合かどうかを返す(setAがsetBを包含するか?)setA.isDisjointFrom(setB):互いに素かどうかを返す(setAとsetBに共通要素がないか?)
メソッド名はいずれも数学の集合で使われる用語です。馴染みがないと難しいと感じるかもしれませんが、曖昧さが排除されるためコードの意図が明確になります。AIがコードを読み取る時にも、より正確に理解できるようになります。
配列とは何が違う? Setを使うメリット
Setの新しい集合演算のメソッドは、配列のメソッドと比較してどう違うのでしょうか? シンプルな例で次の3つを比較してみましょう。コードの分量だけでなく、意図のわかりやすさの観点でもチェックしてみてください。
- ① Arrayを単純にfor文で逐次処理するコード
- ② Arrayのfilterやincludesを使って書き換えたコード
- ③ Setの集合演算を使って書き換えたコード
例題は2人のユーザーの興味分野から、共通の興味を見つける処理です。
const userA = ["JavaScript", "React", "Node.js", "Python", "機械学習"];
const userB = ["Python", "機械学習", "Docker", "Kubernetes", "Go"];
① for文で逐次処理するコード
// 共通の興味を見つける
const commonInterests = [];
for (const interestA of userA) {
for (const interestB of userB) {
if (interestA === interestB) {
commonInterests.push(interestA);
break; // 見つかったので内側のループを抜ける
}
}
}
console.log("共通の興味:", commonInterests); // ["Python", "機械学習"]
さすがにこのような書き方を目にすることは減りましたが、複雑なコードや他の条件によっては、ついループで書いてしまうこともあるかもしれません。性能と可読性のどちらで見てもあまり良い書き方ではないでしょう。
② 配列のfilterやincludesを使ったコード
// 共通の興味を見つける
const commonInterests = userA.filter((interest) => userB.includes(interest));
console.log("共通の興味:", commonInterests); // ["Python", "機械学習"]
この書き方はよく見かけますね。①よりも簡潔になりましたが、includesでヒットしたものをfilterする、という意図の読み解きは必要です。
③ Setの集合演算を使ったコード
const setA = new Set(userA);
const setB = new Set(userB);
// 共通の興味を見つける
const commonInterests = setA.intersection(setB);
console.log("共通の興味:", commonInterests); // Set { "Python", "機械学習" }
最後はSetの集合演算を使ったコードです。単に行数が減っただけでなく、intersection=「共通部分を求める」という意図が明確になりました。コードのレビューや修正時にも、より明確に理解できるようになるはずです。
また、この例では最後の出力をArrayに変換せずにSetのままにしています。[...commonInterests]で配列に変換することはできますが、Setのままにすることで結果が重複を含まないことを明示できます。
Setの集合演算を使ってみよう
実際の開発でSetの集合演算が活躍する場面を見てみましょう。今回は音楽のプレイリストを例にします。
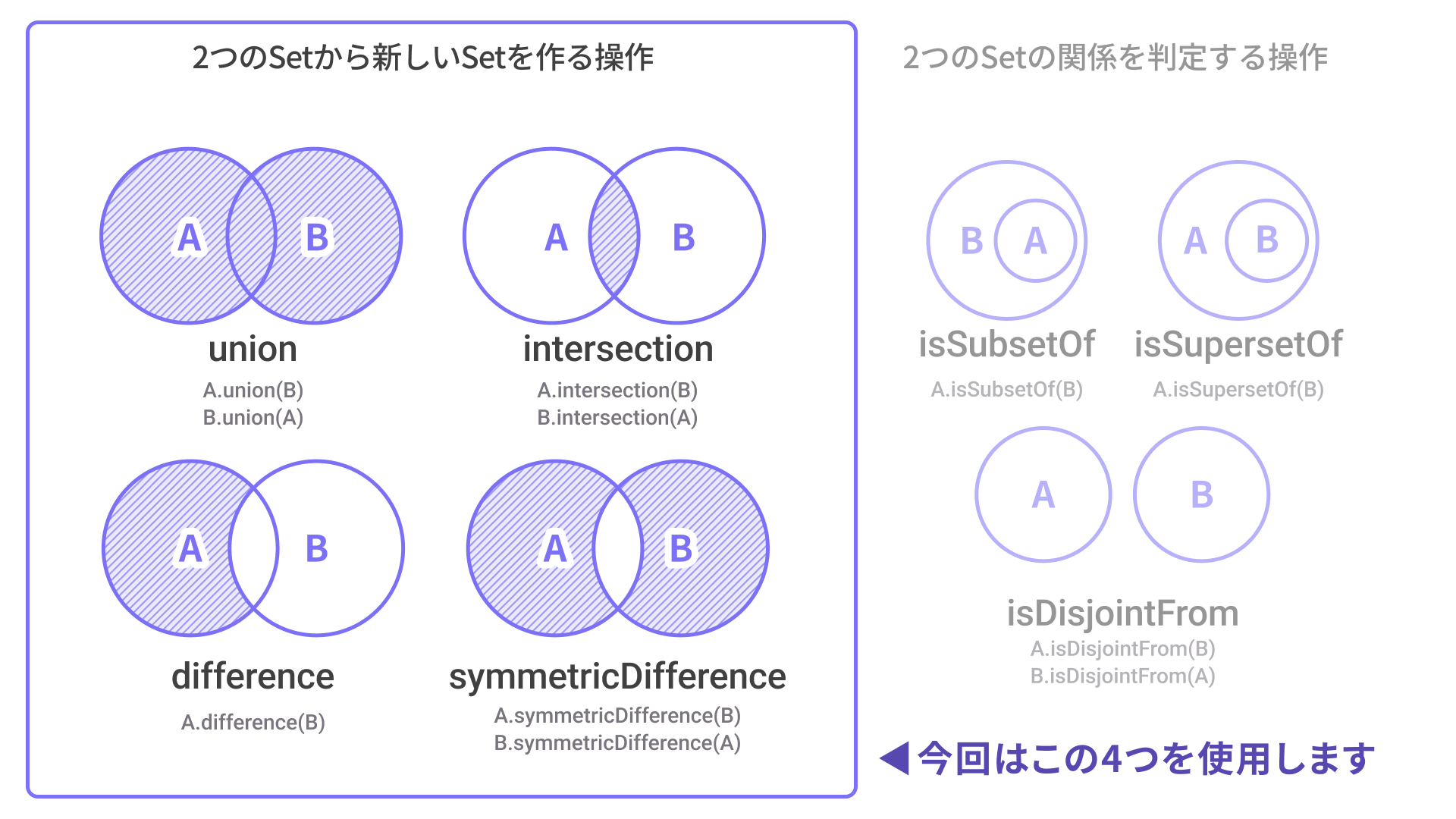
先ほど紹介したSetのメソッドのうち、「2つのSetから新しいSetを作成する操作」の4つがすべて登場します。図と合わせてチェックしながら読み進めてください。
▼ この作例で使用するSetの集合演算メソッド
// すべての楽曲リスト
// 作例を簡単にするため、曲名をidとしています。曲名の重複はないものとします。
const songList = [
{ id: "夕暮れ通り", tags: new Set(["pop", "chill"]) },
{ id: "深夜のセッション", tags: new Set(["jazz", "instrumental"]) },
{ id: "疾走ドライヴ", tags: new Set(["rock", "energetic"]) },
{ id: "雨音レコード", tags: new Set(["lofi", "chill"]) },
{ id: "都会の抜け道", tags: new Set(["jazz", "funk"]) },
{ id: "メロウな午後", tags: new Set(["pop", "retro"]) },
{ id: "電光ストンプ", tags: new Set(["rock", "electronic"]) },
{ id: "眠れぬ星たちへ", tags: new Set(["ambient", "chill"]) },
];
// ユーザーの情報
const likedTags = new Set(["pop", "jazz"]);
const dislikedSongs = new Set(["疾走ドライヴ"]);
すべての楽曲のリストと、ユーザーの情報(好きなタグと嫌いな曲)を定義します。曲の一覧やタグは単純な配列で定義してももちろん構いませんが、今回は「重複なし」であることを明示するために最初からSetを使っています。
ではまずここから、自分の「お気に入りリスト」を作成してみましょう。
// 好きなタグを含む曲
const favoriteTagSongs = new Set(
songList
// 好きなタグを含むか?でフィルタ
.filter((song) => song.tags.intersection(likedTags).size > 0)
.map((song) => song.id)
);
// 自分のお気に入りリスト = 嫌いな曲は除外
const favoriteSongs = favoriteTagSongs.difference(dislikedSongs);
// 出力
console.log("お気に入りリスト:", favoriteSongs);
// Set {"夕暮れ通り", "深夜のセッション", "都会の抜け道", "メロウな午後"}
まず、すべての楽曲から好きなタグを含む曲を抽出します。song.tagsとlikedTagsに重なりがあるかどうかは、intersectionメソッドで確認できますね。
その後、differenceメソッドで嫌いな曲を除外します。filterの中で両方の操作を行うこともできますが、最後に明示的にdifferenceすることで、「嫌いな曲は除外」という意図が明確になります。
次に、友達のプレイリスト情報を追加して「一緒に聴くリスト」を作成してみましょう。
// 友達の情報
const friendPlaylist = new Set(["疾走ドライヴ", "メロウな午後", "夕暮れ通り", "眠れぬ星たちへ"]);
const friendDislikedSongs = new Set(["電光ストンプ"]);
友達にも絶対聞きたくない曲があるので、必ず除外しないといけません。先に二人の嫌いな曲を結合しておくのが良さそうです。
// 二人の嫌いな曲
const ourDislikedSongs = dislikedSongs.union(friendDislikedSongs);
二人とも好きな曲のリストはintersectionメソッドで作成できます。
// 二人とも好きな曲だけをまとめた「シンクロリスト」
const syncedFavorites = favoriteSongs
.intersection(friendPlaylist)
.difference(ourDislikedSongs);
console.log("友達と一緒に聴く:シンクロリスト", syncedFavorites);
// Set {"夕暮れ通り", "メロウな午後"}
differenceメソッドで二人の嫌いな曲を明確に除外できているので安心ですね。
もうひとつ、お互い相手のプレイリストにしかない曲のリスト「ディスカバーリスト」を作成してみましょう。
// お互いにしかない曲を全部混ぜた「ディスカバーリスト」
const discoveredFavorites = favoriteSongs
.symmetricDifference(friendPlaylist)
.difference(ourDislikedSongs);
console.log("友達と一緒に聴く:ディスカバーリスト", discoveredFavorites);
// Set {"深夜のセッション", "都会の抜け道", "眠れぬ星たちへ"}
こちらはintersectionをsymmetricDifferenceに変えるだけですね。symmetricDifferenceは利用頻度も低い上にちょっと覚えにくい英語ですが、unionがOR、intersectionがAND、symmetricDifferenceがXORと覚えておくとエンジニア的には馴染みやすいかもしれません。
Setの落とし穴と対策
Setの集合演算は便利な反面、落とし穴もあります。
数学の集合には順序がないが、Setの集合演算は順序を維持する
一般的に数学の集合には順序がありませんが、Setの集合演算は順序を維持します。今回紹介した集合演算では順序は意味を持ちませんが、Set自体には入力した時の順序が保持されています。
以下の例のように集合として等価であっても、配列に変換した時に同一とは限らないので注意しましょう。
const isSameSet = (setA, setB) => {
return setA.size === setB.size && setA.isSubsetOf(setB);
};
const isSameArray = (arrayA, arrayB) => {
return (
arrayA.length === arrayB.length &&
arrayA.every((element, index) => element === arrayB[index])
);
};
const setA = new Set([1, 2, 3]);
const setB = new Set([3, 2, 1]);
console.log(isSameSet(setA, setB)); // true: 集合としては等価
console.log(isSameArray([...setA], [...setB])); // false: 配列にすると等価ではない
順序を維持する仕様は、配列と相互に変換する際の予期せぬ動作を避けるためにはありがたいものです。ただし、Set自体を順序付きのリストとして扱うと、とくに集合演算の利用時に意図がわかりにくくなる可能性があります。
特段の理由がなければ、数学の集合と同様に、Setには順序がないものとして扱う方が良いでしょう。
AIはまだ新しいSetの機能を十分に知らない
Setの集合演算はまだ新しい機能です。2025年6月時点の主要なAIの多くはSetの集合演算が正式にリリースされたことを知りません。検索機能を持っているAIは質問すれば適時調べて新しい情報を教えてくれますが、検索できないものやタブ補完等では古い知識ベースで応答されます。
▼ GitHub Copilotの回答例(GPT-4.1 / 2025年6月4日時点)
いいえ、JavaScriptの標準Setオブジェクトには、
ご提示のメソッド(union, intersection, difference, symmetricDifference, isSubsetOf, isSupersetOf, isDisjointFrom)は実装されていません。
これらの集合演算は自分で関数を作るか、外部ライブラリ(lodash, immutable.jsなど)を使う必要があります。
ただし、集合演算の概念や用語自体はどのAIも知っているため、新しい機能で書いたコードは適切に理解してくれます。書いたコードのレビューや説明を求めた場合も、Setの集合演算を使った方がより簡潔で明確な回答が得られる傾向があるようです。
将来の保守性のためにも、当面は人間がサポートして新しい機能を適切に使うよう、アシストしていくのが良いでしょう。
まとめ
Setの集合演算は、配列メソッドだけを使用した場合と比べて、意図が明確で読みやすく保守しやすいコードが書けます。本記事で紹介したメソッドはすべて2024年にBaselineに入っており、そろそろ実務でも「使える」機能です。まだAIのサポートは不十分なケースもありますが、将来のためにも積極的に使っていきましょう。

