
「機械学習」や「深層学習」が流行ってますが、プログラミングではじめるにも「難しそう」と印象を持ってる方は多いのではないでしょうか。本記事では画像認識をテーマに、ウェブのフロントエンジニアが手軽に試せるサービスを紹介します。
Visual RecognitionとはIBMが提供しているWatsonの画像認識APIサービスです。IBM Watsonには音声認識や音声合成、テキスト分析などWebサービスで使えるさまざまなAPIが用意されています。また、これらはIBM Cloudライト・アカウントに登録することで、ライトプランに対応したサービスは無期限・無料で利用できます。
本記事では、Watson APIの1つである画像認識API「Visual Recognition」について、サンプルを交えながら解説します。
画像認識とはパターン認識技術の1つ
画像認識技術とは、写真や動画の中から対象物を抽出し、画像に何が写っているかを識別するパターン認識技術の1つです。
人間は、画像を見れば何が写っているかをすぐに理解できますが、コンピューターには理解できません。そのため、コンピューターにたくさんの画像を与えてそこから対象物の特徴を学習させていくことで、物体・情景・顔などさまざまなものを分析・認識します。
Visual Recognitionは、すでに学習した状態でサービスが提供されているため、すぐに利用できます。また、学習するための画像を準備すれば、ディープラーニングを使用して独自の画像判別モデルも作成できます。
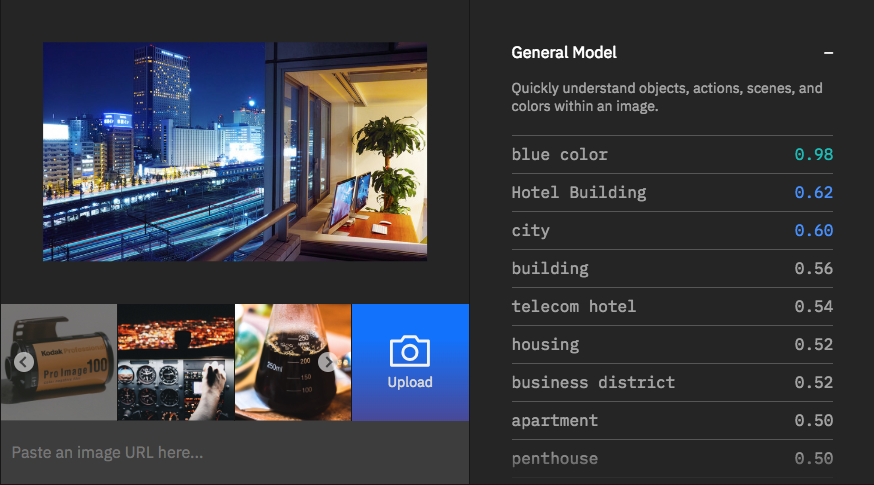
▲ Visual Recognitionは、公式デモサイト(英語)でブラウザにて試すことができます。アップロードした画像から、画像に含まれている要素を自動的に抽出されることが確認できます。
画像認識を試してみる
- JavaScriptで画像に含まれる要素を分析 -
それでは、画像認識APIを試してみましょう。事前準備として、IBM Cloudのアカウントを作成してください。ライトプランの利用であれば、クレジットカードの登録も不要なため、すぐに登録できます。
Visual Recognitionのサービスを作成
アカウント作成後、Visual Recognitionのサービスを作成します。サービス名は任意で設定してください。ライトプランの場合、デプロイする地域は選べず「米国南部」、リソース・グループは「Default」となります。
https://console.bluemix.net/catalog/services/visual-recognition
サービスの作成が完了すると、資格情報が表示されます。後ほどapikeyとurlの情報が必要となりますので、その際はこちらの情報を利用します。

画像認識プログラムの作成
Node.jsを使って画像認識プログラムを作成します。Visual Recognitionは、Node.js以外にも、Swift、Android、PHP、Python、Java、Unity、.NETのSDKが準備されており、APIリファレンスも用意されているため、他の言語でも簡単に利用可能です。この記事で解説するサンプルはGitHubからダウンロードできます。
事前にNode.jsをインストールし、コマンドラインを使う準備をしておいてください。
- 公式サイトからNode.jsをインストールします
- コマンドラインを起動します
(macOSだと「ターミナル」、Windowsだと「コマンドプロンプト」)
任意の場所にフォルダーで次のコマンドを実行し、プロジェクトの設定情報が記述されたpackage.jsonファイルを生成します。
npm init -y
次にSDKのインストールを行います。次のコマンドを実行しインストールをしてください。
npm i -D watson-developer-cloud
これでプロジェクト環境の準備が整いました。次の内容でindex.jsというJavaScriptファイルを作成します。コード内のiam_apikeyとurlの値は、サービス作成時に発行された資格情報の値を入力してください。
▼index.js
const VisualRecognitionV3 = require('watson-developer-cloud/visual-recognition/v3');
const fs = require('fs');
// 資格情報を設定しVisualRecognitionオブジェクトを作成
const visualRecognition = new VisualRecognitionV3({
version: '2018-03-19',
'iam_apikey': "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'url': 'https://gateway.watsonplatform.net/visual-recognition/api',
});
// 画像認識を行う対象の画像を読み込む
const images_file = fs.createReadStream('images/office.jpg');
// 画像認識APIへ付与するパラメータを準備
const params = {
images_file: images_file, // 画像認識を行う対象画像を指定
accept_language: 'ja' // 認識結果を日本語で出力
};
// 画像認識を実行する
visualRecognition.classify(params, (err, response) => {
if (err) {
console.log(err);
return;
}
// 返却されたJSONデータを出力
console.log(JSON.stringify(response, null, 2));
});
サンプルコードは、弊社オフィスの写真を画像認識APIに送信し分析するデモです。

プログラムを実行してみましょう。次のコマンドを入力し、作成したプログラムを実行します。
node index.js
次のJSONデータが返却されました。画像認識に成功しているようです。オフィスから見えるホテルやオフィス街も認識しており、右半分に写っている弊社オフィスもペントハウス(マンションやホテルでもっとも価格の高い最上階の部屋)として認識されています。scoreの数値はAPIが判断した「確信度」です。確信度は0.0〜1.0の数値で算出され、確信度が0.5以上のものがclassとして返却されます。
{
"images": [
{
"classifiers": [
{
"classifier_id": "default",
"name": "default",
"classes": [
{
"class": "ホテル建築",
"score": 0.622
},
{
"class": "都市",
"score": 0.604
},
{
"class": "建物",
"score": 0.561
},
{
"class": "オフィス街",
"score": 0.516
},
{
"class": "ペントハウス",
"score": 0.5,
"type_hierarchy": "/住居/アパート/ペントハウス"
},
{
"class": "アパート",
"score": 0.503
},
{
"class": "住居",
"score": 0.522
},
{
"class": "青色",
"score": 0.976
}
]
}
],
"image": "office.jpg"
}
],
"images_processed": 1,
"custom_classes": 0
}
画像認識だけならわずか20行程度のJavaScriptのコードだけで実現できます。とても簡単に利用できるので、写真を題材としたようなウェブサービスの開発に活用できそうだと感じました。
機械学習を試してみる
- クッションの種類を学習させ独自の画像認識を -
Visual Recognitionは、学習用の画像を用意しトレーニング(機械学習)させることで、独自の画像認識モデル(カスタム分類器)を作成できます。弊社オフィスにあるアドビのクリエイティブクラウドのクッションで機械学習をおこない、判別できるかを試してみます。

学習用の画像ファイルを準備する
トレーニングには、正例(positive)の画像と負例(negative)の画像をそれぞれ準備する必要があります。本記事ではchusionというカスタム分類器を作成し、正例として「XD」「Fl」「Ps」の3つクラスを作成し、負例として(その他のクッション)の画像を用意します。
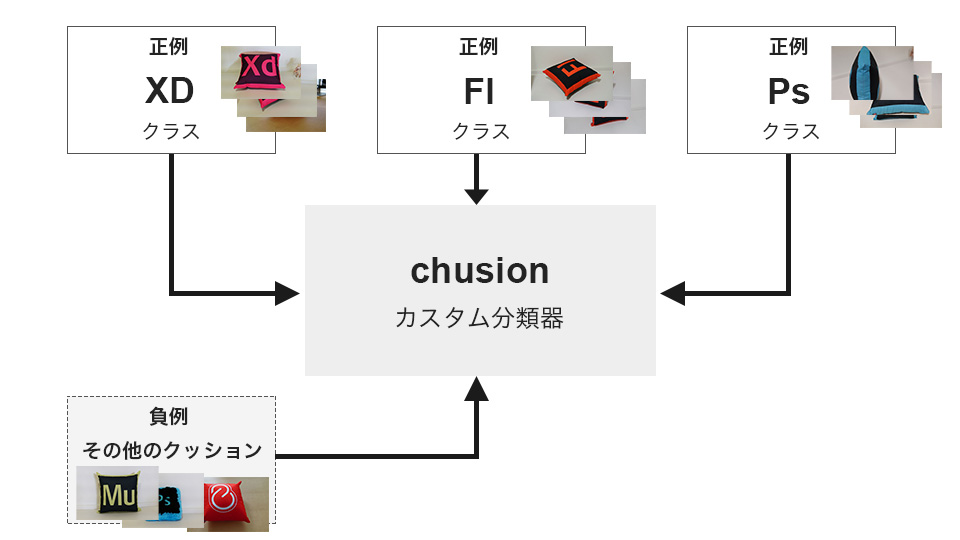
また、学習用の画像は以下のルールに沿って準備する必要があります。
- 画像の形式は、
.jpgまたは.png - 画像サイズは32x32以上(推奨は224x224以上)
- 画像容量は10MB以内
- 正例、負例とも10個以上、10,000個以内の画像を用意する
※良好なトレーニングを行う方法については、記事「Best practices for custom classifiers in Watson Visual Recognition - IBM Cloud Blog」に詳しく記載されています。
学習用の画像を送信しトレーニングを行う
画像認識だけでなくトレーニングもAPIが用意されているため、Node.jsから実施できます。次の内容でtraining.jsというJavaScriptファイルを作成します。
▼training.js
const VisualRecognitionV3 = require("watson-developer-cloud/visual-recognition/v3");
const fs = require("fs");
// 画像認識を行う対象の画像を読み込む
const visualRecognition = new VisualRecognitionV3({
version: "2018-03-19",
iam_apikey: "xxxxxxxxxxxxxxxxxxxxxxx",
url:
"https://gateway.watsonplatform.net/visual-recognition/api"
});
// トレーニングAPIへ付与するパラメータを準備する
const params = {
// カスタム分類器の名称を定義
name: "cushion",
// 正例を指定(xdとflとpsのクラスを定義し正例の画像を添付)
xd_positive_examples: fs.createReadStream(
"./data/xd_positive_examples.zip"
),
fl_positive_examples: fs.createReadStream(
"./data/fl_positive_examples.zip"
),
ps_positive_examples: fs.createReadStream(
"./data/ps_positive_examples.zip"
),
// 負例を指定
negative_examples: fs.createReadStream(
"./data/negative_examples.zip"
)
};
// トレーニングAPIを実行する
visualRecognition.createClassifier(
params,
(err, response) => {
if (err) {
console.log(err);
return;
}
console.log(JSON.stringify(response, null, 2));
}
);
正例の画像と負例の画像は、それぞれzipファイルにして送信します。パラメーター名には指定があり(任意のクラス名)_positive_examplesという名称で設定します。負例の画像はnegative_examplesで指定します。
プログラムを実行してみましょう。次のコマンドを入力し、作成したプログラムを実行します。
node training.js
実行すると、次のJSONファイルが返却されます。cushionという名称のカスタム分類器が作成され、ステータスがtrainingになっていることが確認できます。トレーニングには数分ほどかかり、ステータスがreadyになれば作成したカスタム分類器を利用できます。ステータスの確認は、visualRecognition.listClassifiersのAPIで確認できます。
{
"classifiers": [
{
"classifier_id": "chusion_943773566",
"name": "cushion",
"status": "training",
"owner": "ddc60ebb-9626-499a-b86d-bdc574f366be",
"created": "2018-05-28T07:08:47.899Z",
"updated": "2018-05-28T07:08:47.899Z",
"classes": [
{
"class": "fl"
},
{
"class": "xd"
},
{
"class": "ps"
}
],
"core_ml_enabled": true
}
]
}
本記事のデモでは、正例・負例あわせて300枚程の画像を準備しました。また学習の精度が高まるように、色々な角度で撮影するだけでなく、明るい場所や暗い場所、テーブルの上、床の上などの異なる場所で撮影しました。さまざまなパターンの画像を用意することで、ディープラーニングにより、短時間で少ない枚数でも高い精度の画像認識を実現しているようです。
▼準備した画像の一例(正例のXdの画像)

学習結果を使って画像認識を実施する
トレーニングには使用していないクッションの画像で正しく判定できるか確認してみましょう。「正例として学習したXdのクッション」と「学習していないDwのクッション」の画像で、それぞれどのような結果になるか確認してみましょう。

さきほど作成したindex.jsのparamsにclassifier_idsというパラメーターを追加します。設定する値はトレーニングを実施した際に返却されたJSONファイルに記載されているclassifier_idの値を記述します。
▼index.js
const VisualRecognitionV3 = require("watson-developer-cloud/visual-recognition/v3");
const fs = require("fs");
// 資格情報を設定しVisualRecognitionオブジェクトを作成
const visualRecognition = new VisualRecognitionV3({
version: "2018-03-19",
iam_apikey: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
url:
"https://gateway.watsonplatform.net/visual-recognition/api"
});
// 画像認識を行う対象の画像を読み込む
const images_file = fs.createReadStream(
"images/chusion_xd.jpg"
);
// 画像認識APIへ付与するパラメータを準備
const params = {
images_file: images_file, // 画像認識を行う対象画像を指定
accept_language: "ja", // 認識結果を日本語で出力
classifier_ids: ["chusion_943773566"] // トレーニングを行ったカスタム分類器のIDを指定
};
// 画像認識を実行する
visualRecognition.classify(params, (err, response) => {
if (err) {
console.log(err);
return;
}
// 返却されたJSONデータを出力
console.log(JSON.stringify(response, null, 2));
});
学習済みのXdのクッションを判定
学習済みのXdのクッションを認識できるか確認します。

次のコマンドを入力しプログラムを実行します。
node index.js
画像認識APIをコールすると次のJSONデータが返却されました。確信度0.871でxdのクッションであると判断しています。期待通りの動作です。
{
"images": [
{
"classifiers": [
{
"classifier_id": "chusion_943773566",
"name": "chusion",
"classes": [
{
"class": "xd",
"score": 0.871
}
]
}
],
"image": "chusion_xd.jpg"
}
],
"images_processed": 1,
"custom_classes": 3
}
未学習のDwのクッションを判定
学習していないDwのクッションではどのように判定されるのか確認してみます。

画像認識APIをコールすると次のJSONデータが返却されました。期待値通り、学習した「Xd」「Fl」「Ps」ではないと判断されているようです。
{
"images": [
{
"classifiers": [
{
"classifier_id": "chusion_943773566",
"name": "chusion",
"classes": []
}
],
"image": "chusion_dw.jpg"
}
],
"images_processed": 1,
"custom_classes": 3
}
複数のクッションが写った画像で検証する
単体のクッションの画像での画像認識は問題なく動作したため、次は複数のクッションが写っている画像で画像認識の検証をしてみます。学習済みの「Xd」と「Fl」のクッションと学習していない他のクッションが複数写った画像で画像認識を行います。

画像認識の結果、次のJSONデータがAPIから返却され、XdとFlのクッションが認識に成功していることがわかります。Xdのクッションがメインで写っているため確信度も高い数値となっています。Flのクッションは少し隠れているため確信度は低いですが、画像に写っていることは認識できています。高い数値で判断するにはもう少し学習の精度を上げる必要があるようです。
{
"images": [
{
"classifiers": [
{
"classifier_id": "chusion_202071019",
"name": "chusion",
"classes": [
{
"class": "fl",
"score": 0.27
},
{
"class": "xd",
"score": 0.822
}
],
"image": "chusions.jpg"
}
],
"images_processed": 1,
"custom_classes": 3
}
おわりに
IBM Watsonを使うことで機械学習を簡単に利用でき、高い精度の画像認識を行うことができました。JavaScriptとNode.jsだけで簡単に利用できるのもウェブのフロントエンドエンジニアにとって魅力的です。IBM Watsonには音声認識や音声合成、テキスト分析などのAPIも準備されているので、Webサービスに活用してみてはいかがでしょうか。
人工知能や機械学習の有名な事例については記事「ちゃんと理解してる? 最近よく耳にする「AI」や「ディープラーニング」について調べてみた」にまとめているので、あわせて参照することで理解が深まると思います。
